ORB Visualization
(soon)
4/11/2004 12:54 PM
OntologyStream Inc, the Creator of the Anticipatory Web
A Systematic Review of all
Software Patents
Presentation on Anticipatory
Web Technology
and
OntologyStream Inc
OntologyStream Inc, the Creator of the Anticipatory Web
OntologyStream Inc is quite different from other technology start-ups. Our technical and scientific know-how comes from an emerging community-based consensus regarding the technical need to separate (a) the measurement of invariance in data and (b) human annotation of the meaning of patterns of invariance.
A general scholarly consensus has not been achieved regarding the nature of human knowledge and the nature of relevant computer-based algorithms; such as those in artificial neural networks, genetic algorithms, natural language processing, machine translation, and machine learning. Those who would wish to design and operate computer-aided control of complex systems are hindered by the absence of scholarly agreement. Government and industry procurements have been very costly and often ineffective.
In particular the issues of precision and fidelity of computer-based representation of the human experience of knowledge are not fully delineated in a natural science paradigm. In some cases, what is delineated are various forms of science fiction, discredited by modern natural science but still taught by many computer science departments.
There are deep differences of opinion and yet very little effort undertaken to unify the natural sciences with computer science. In fact federal funding practices, over the past four decades, have all but required any natural science related to cognition or social phenomenon to have a formal foundation consistent with strict principles of reductionism. These funding practices ignore various advances in natural science, which strongly suggest that the type of formalism advocated by the great mathematician David Hilbert (1862-1943) and the traditions of logical positivism, simply fails to model the phenomenon of emergence.
We agree that some degree of reduction to formalism is valuable, but we also point to works by many scholars regarding the fundamental differences between engineered systems and natural living systems. The role of reductionism to a strict formalism is a difficult point to address unless there is a proper educational background on which to build. But without an understanding of natural complexity, often found in conjunction with emergence, certain control problems are not addressable. Often, the current practice is to introduce statistical models where the acquisition of data excludes specific information about individual differences, and thus removes a formal path to the phenomenon under study.
With an understanding of natural complexity, one has a framework for computer-assisted translation of diplomatic messages and other “hard” natural language processing (by computer/human mutual assistance) tasks. But the simulation of natural complexity with Hilbert-type mathematics produces routes to uncertainty as a formal consequence (for more on this see I. Prigogine, “End of Certainty”). The introduction of certain works from category theory weakens the foundations of Hilbert mathematics so that the issue of complexity, completeness and consistence are addressed as an induction of new formalism in real time. The induction requires human-centric information processing (HIP) and computational structure encoding the categories of invariance seen in a transparent measurement of phenomenon, as computer encoded data about invariances of substructural elements, and a computational structure modeling the set of potential (event) chemistries. The completion of James Stuart Mill’s (1806-1874) cannons can then be used to produce deductive inferences about the function/behavior of complex compounds given some knowledge of the presence of substructural elements.
The world is turned up side down, and many so called
"hard" problems are restated in an unexpected form.
This was the solution approached by several schools of thought, and which leads to the notion of computer aided mutual induction. For mutual induction to occur, the human must be involved in the remediation of uncertainty in non-Hilbert mathematics, and the consequences of this remediation are a specification of a formalism that is descriptive and highly situational. This process must be transparent to the human. Because of this transparency the informational induction process itself will be, due to the requirement of transparence, much easier to understand than statistical models of the phenomenon under study.
Both a national educational project is needed and a shift in information technology paradigms is needed before the notion of complexity will be commonly understood.
The issues seem more difficult that might be, because of
the confusion that exists both within the computer science community and within
the natural science community. As
discussed elsewhere, the role of commercial television has further limited
society’s ability to deal with issues of natural complexity, and have replaced what
would be unaided positive intuitions about the nature of life with simply
minded social philosophy used to support a false sense of community. The shift in information technology requires
a rejection of this false sense of community with both a full acceptance of
multi-culturalism and open transparency on social discourse.
The open transparency on social discourse is needed so
that any one community can live without fear from another community who happens
to hold fundamentally different cultural perspectives. Open transparency on social discourse is
also needed because both the intelligence communities and commercial enterprises
have discovered how to see and manipulate the social discourse using web
harvesting tools and automated generation of subject indicators.
Using web harvests to model social discourse is a complex process where the separation between measurement and interpretation is needed. Once this separation is clearly established, then machine representation of structure can be presented for human viewing as topological neighborhoods of graphs. The resulting work produce produces very high resolution and very high fidelity subject matter indicators.
Figure1: Two topological neighborhoods of an Orb
These neighborhoods are “incomplete” representations of human knowledge, and thus the topological graphs serve as cognitive priming resulting in what Prueitt has called “mutual induction”. A series of mutual induction steps occur as a natural sequence leading to the creation of new information, or to the location of information. This computer-mediated process follows exactly the model of human behavioral and cognitive capacities.
Artificial Intelligence seeks to ground intelligent control in long chains of deductive reasoning and in first order predicate logics. Semantic Web philosophy holds onto some of this false desire. This strategy will continue to fail, not because the deductive reasoning systems are not yet properly designed, but because no computation can properly simulate the natural cognitive acuity of a human being. Semantic Web visions can be reified by natural science only if the founders of the Semantic Web community learn more about what natural science says regarding the issues of complexity and emergence.
The separation of measurement processes from an assignment of meaning is consistent with several data processing standards including the Topic Map standard and the Human Mark-up Language standard. The core principle is both philosophical and functional. The principle reminds us that human cognitive acuity has not been reproduced by any computer program, and that human in the loop systems will be far more productive than current generation artificial intelligence or Semantic Web technology.
We use a number of new terms as part of a brand development philosophy. One of these is “Synthetic Intelligence”. The term is used to contrast our philosophical grounding from the academic discipline of Artificial Intelligence. Another term is “Knowledge Operating System” where our brand language develops the notion of action perception cycles involving human reification of algorithmically determined aggregations of sub-structural invariance.
Formation
Our formation needs are quite different from typical technology start-ups. Differences stem from the following:
1) The BCNGroup Inc provides low cost knowledge science peer review of emerging innovations in a market that does not exist today. Most of our consulting income has come from the evaluation and extension of patents.
2) Each of many innovations can be packaged as part of a technical / capabilities foundation for the knowledge technology revolution. BCNGroup Inc and Ontologystream Inc work together to provide very clear descriptions of innovations and to place the innovations into a larger model of capabilities and techniques related to knowledge creation, knowledge management and/or knowledge propagation. Publicly available tutorials on how the innovations are used in software context are developed, and broad based educational materials are developed to spread an understanding of specific innovations.
3) Ontologystream Inc will hold Intellectual Property and license the use of this property to start-ups that it will help found. Initial help is made by identifying low cost management, accounting and financial support for preliminary work on software expressions of the innovations. These start-ups will develop horizontal capability through .Net and Java independent Application Program Interfaces (API)s. Each of the APIs will have commonalities to each other and will use only Open Source software tools, and only as minimally required. The management, accounting and financial support will be modeled after templates that are designed the cash out early investment at a target of 150% within six months and leave the inventor(s) in control of at least 50% of a functioning corporation.
4) Each of the API’s will be consistent with the concept of a Knowledge Sharing Foundation, and will be brought into a distance-learning environment designed to teach children (K-12) about Peer-to-Peer networks and the knowledge sciences. Both the inclusion into the Knowledge Sharing Foundation infrastructure and the K-12 curriculum will give immediate branding exposure to the innovation and the software designed based on the innovation. The K-12 curriculum and the Peer-to-Peer software will boot any computer into a minimal Linux node.
5) The BCNGroup Inc and OntologyStream Inc will exist in the background and not be involved in extensive product marketing. Our products are companies. Thus the management team will be smaller and the marketing budget will be even smaller. Everything will be focused on placing a bright light on the nature of computer science innovations and on the actual performance of the software systems we endorse.
6) The organizational structure of BCNGroup Inc and OntologyStream Inc will have two faces. One face will be oriented towards the innovator and the scholars. The other face will be oriented towards the capital formation community. We will not follow the market. We will lead the market.
7) It is our observation that as much as 90% of information technology start-up companies expenditures is made on marketing and management costs. Most of these costs are necessary in an environment where business survival depends on memberships in informal monopolies. However, in a market where a rapidly growing public awareness is driving the development of the market, membership in existing monopolies is in fact perceived as a negative. The markets will select based on transparent branding language and on performance.
A Systematic Review of all Software Patents
In one hundred years there will be no legally enforceable software patents. The completion of computer science will have much the same nature as the completion of the elementary theorems of basic calculus. It will be a standard curriculum which everyone will know.
An emerging community consensus has developed around the observation that the software markets are hopelessly confused by incoherent awarding practices by patent offices. Figure 1 illustrates the conjecture that at the heart of all software patents are a few core mathematical principles.
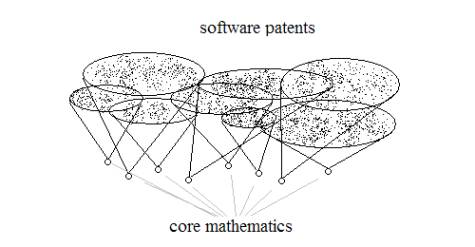
Figure 1: illustrating the dependency of software patents
on core mathematical principles
Patents are expressed as processes that run on a computer and often depend strongly on these core mathematical principles. Once the core mathematical principles are clearly identified three things will happen.
1) Many of the current patents will be easy to challenge in court, thus reducing the power of monopoly over software.
2) Some key patents will be strengthened, making them more important
3) All software patents are mapped to core mathematical concepts making it easier to innovate on existing patents and harder to demonstrate single ownership of reductions to practice.
After a through review, taking perhaps 10 years, only a few validated software patents will exist, or will be considered enforceable. Patents will be organized into categories so that objective evaluations can be rendered and fair market evaluation made for the use of the patents. The core principles on which categories of patents are based will be studied as part of a mathematical discipline.
The mapping of patent disclosures will afford new industry based on easy access to technical information about computers.