ORB Visualization
(soon)
4/11/2004 7:15 PM
HIP architecture for the control of complex manufacturing systems
Real time analysis and human
tacit knowledge
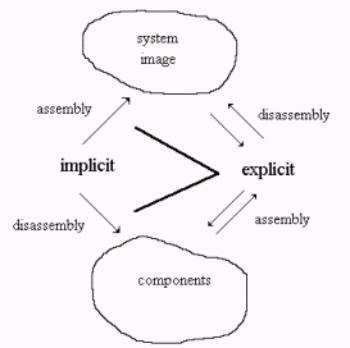
Figure: Separation of implicit
representation from explicit experience.
I-RIBs and Orbs
Many biologists view the action-perception cycle as the most essential aspect of natural intelligence. In fact, if one looks closely at various aspects of natural intelligence, one sees that perception, cognition and movement are separately architected. Likewise memory, awareness and anticipation are separated systems.
The innovations by knowledge scientists have lead to tri-level computer process architecture and actionable intelligence process architecture that follows the science of natural intelligence in ways that are very different from classical machine learning and artificial intelligence system design. The science of natural intelligence also departs radically from database constructions.
We make a precise statement about the radical differences we propose for Human-centric Information Production (HIP). We provide hyper links to demonstrations of some part of the set of core mathematical concepts on which HIP is grounded.
HIP requires that the computer itself be open to programming by the user while the user produces information. We compare HIP technology to a typewriter. Without a natural intelligence pressing the keys, no information is produced. In fact, like in the case with a typewriter, the appearance that the typewriter” is producing information is an illusion. The origin of natural intelligence may be mistaken to occur in the interaction between the computer and the human. This has lead to the myth of Artificial Intelligence (AI).
The computer can be more dynamic that the typewriter, and can support the memory formation and the anticipation of natural intelligence. Without falling into the mistake of AI we examine very carefully the steps involved in using the computer to create a record of the invariances in data. These steps are categorized in the first two aspects of a nine aspect Actionable Intelligence Process Model (AIPM).
We have written extensively about the AIPM, but the most essential novelty are these two aspects. Both consist of duals, instrumentation/measurement and encoding/representation. It is with these two sets of duals that we have the greatest departure from classical control systems.
Instrumentation has to occur to allow measurement, but measurement is actually instrumented as a function of measurement. The flaw in relational database usage in the control of complex manufacturing processes is that the instrumentation structures how data is acquired and preserved. Often the design of the data schema produces a one sided compromise where computer scientists say what they can do and the natural scientists acquiesce. Standard practice is to not directly acquire all data but to build inferential chains that produce data from a small set of actual inputs.
The alternative is to encode precisely that data, of which one has instrumented measurement, into a set of ordered triples having the form < a, r, b > where a and b are “locations” and r is a relational operator.
The form “< a, r, b > “ is called a syntagmatic unit, in reference to extensive literatures on this data construction from formerly classified Soviet cybernetics and applied semiotics. It is a simple exercise to show that any relational database can be written as a set of these triples, and that such a set has information sufficient to reconstitute the exact same relational database. There are many ways of doing this. Likewise it is easy to show the many different organizational schemas can be produced from this set.
It is therefore reasonable to regard the set of ordered triples to be schema independent. In text understanding systems this turns out to be very important in the organization of concept representations. To this day, I am not sure that anyone understands this except for me. It is simple however. Co-occurrence is almost universally used as a way of saying that there is a relationship between two words that are co-occurring. Word a and word b co-occurring is used to imply that there is a relationship between a and b. But is this true? What relationship?
In the case of ordered triples from databases we may have syntagmatic units of the form:
< row, value, column >
The value is the relationship. A little thought reveals that data encoding may be achieved so that information that is repeated is compressed or organized so that less memory is taken up by the set of syntagmatic units that a standard relational database. (Technical note: Hash tables work to achieve part of this organization, but the hash function requires many machine cycles to produce a “hash-key”, there are conflicts over what information is placed where, and for the system to work well, one has to maintain a random distribution of empty hash buckets (to put data into). However, a very simple treatment of ASCII strings as base 64 numbers introduces a key-less hash table having no need for empty hash baskets and no collisions. ) The organization is not as in a database schema, but an organization of things into categorical equivalences based in structure invariances.
We call such key-less hash constructions by the phrase “In-memory Referential Information Bases” (I-RIBs). If the I-RIB is used to encode structural invariance for the purpose of subject matter indicators, then we call these constructions Ontology referential bases (Orbs).
Orbs have been used in the task of controlling parsing measurement to assist the human organization of concept representations. A similar architecture will be used to control the measurement of complex manufacturing processes by providing a means to organize instrumented measurements of those processes.
Text n-gram parsing demonstrates the awkwardness of relational databases when measuring phenomenon and encoding the instrumented measurements. One can look carefully at the Orb notational paper to see a generic model that applies in a more general case then n-gram measurement over the structure of linguistic variation in text.
The more general case is what I have called general Framework analysis (gF analysis). This case works with what I developed as categorical Abstraction (cA) and eventChemistry (eC). These three methodologies, gF, cA, and eC; are present in various literatures but they are hard to find and when found it is hard to place them together into a single unified viewpoint. The Tri-level architecture does create this viewpoint.
HIP must also play an essential role because the first two aspects of the AIPM are designed to measure structure, encode what is measured, and to leave the interpretation of the measured presence of structure to human inspection.
Real time analysis and human tacit knowledge
Knowledge artifacts may exist in a persistent form as language and architecture. Social knowledge may exist independent of individual experience. These are not issues that science has closure on.
However, human experience of knowledge only exists in real time, in a “present moment”. Anticipatory services by a computer are presented to a human not in the abstract but in real time. This is exactly where the notion of Anticipatory Web comes from.
Perception about information derived from past measurements must have a high degree of fidelity to something that is real. Why? Because information transparency and trust are necessary to produce true information about complex measured processes. The computer treats true information the same as information which is not true. Unlike the human, the internal encoding does not carry with it a feeling of emotion. This seems like a truism. However, one can look into various databases produced for scientific work, or for genetics and see that organizational structure is imposed from the beginning, and not as an interpretive act in real time.
One should be able to see what the measured data was, without the inferred structure already present.
Nature separates perception from cognition. The HIP technologies will separate measurement/instrumentation from encoding/interpretation. To suggest how this might be doen we quote from Chapter 3 in Foundations of Knowledge Science (Prueitt – web published).
Examples of perceptual mechanisms include components of the neuronal
and immune systems in mammals. These mechanisms are directed at creating, from
an explicit experience, a decomposition into an implicit representation of the
world and using this representation to maintain a form, i. e. a set of
structural invariance, over a period of time. The causes and properties of
objects would be stored also. For humans, this implicit representation is
stored in multiple memory systems (Schacter & Tulving, 1994) and provides
the basis for various creations of the human mind; including language,
mathematics and logic.
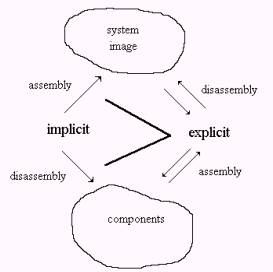
Figure 1: Separation of implicit representation from explicit
experience.
Let us examine the phenomenon of perceptional measurement a bit deeper.
Figure 1 suggests how one applies the three methodologies; gF, cA, and eC, in the production of information about complex manufacturing processes. In various classes of complex manufacturing processes one will be able to identify those characteristics that need to be measured. Of course, the relational databases are used for this purpose. However, there will be additional flexibility in how the measurements are made and due to the very simple XML type encoding as syntagmatic units, various formal relationships can be made to machine ontologies and to other relational databases. Likewise interpretative constructions can be applied after the fact. These interpretative constructions act as chemistries whose rules are applied to Orbs.
Furthermore, the completed logics of Mill can be applied to derive a plausible argument regarding the function of chemistries.