Thursday, September 02, 2004
Manhattan Project to Integrate Human-centric Information Production
Stratified complexity and the
origin of mental/social events, (Prueitt 2002)
Conjecture on Stratification
Synthesis of discussion (edited by several information scientists)
Some key theoretical consideration

A picture of the actual connectivity of the Internet
as measured in one day (June 30th, 2003)
Goddard and Wierzbicka’s work
Here is one of Anna Wierzbicka links
http://www.une.edu.au/arts/LCL/disciplines/linguistics/nsmpage1.htm#model
She published work with Cliff Goddard. One of Goddard's (2002) papers is “The Search for the Shared Semantic Core of All Languages”
http://www.une.edu.au/arts/LCL/disciplines/linguistics/Goddard_Ch1_2002.pdf
Two passages in Goddard’s paper are relevant:
From page 3: The assumption of the “meta-semantic adequacy ” of natural languages can of course be questioned or disputed. But if it is valid, it would have very important consequences for linguistics, and so it deserves to be taken seriously.
From page 7: If we had various independently established natural semantic meta-languages, we could then compare them and establish, on a purely inductive basis, in what respects they were similar and in what respects they were different. Obviously there would be differences – because Polish, Yankunytjatjara, and Lao are different languages.
Not only would we expect the forms of the semantic primes to be different, we would expect various language-specific grammatical rules to be different (e.g. word order, rules of agreement, and inflection). But how extensive would the similarities be? To what extent would it be possible, for example, to match up the meanings embodied in the English primes with those of Polish, Yankunytjatjara, and Lao? To what extent would the combinatorial patterns of the English meta-language have analogues in the meta-languages of other languages?
These questions have been of pressing concern to Wierzbicka and her colleagues since the late 1980s. At root, the fundamental issue is that of universality: the same issue that dominates mainstream discussions of syntax and phonology. As in other areas of linguistics, they work has adopted – and sought to test – the hypothesis that there is substantial universality in both the lexicon and the grammar of semantic meta-language.
This substantial universality might be found not at the in both lexicon and grammar level but in some set of elements of a substructural ontology, such as what Prueitt and Ewell have been discussing.
Cliff Goddard goes on to say:
As mentioned, the ideal position from which to bear on the issue would be to begin with a body of deep semantic analyses carried out on a purely language-internal basis in a range of diverse languages.
But we do not have such work.
There have been many valuable explorations of particular semantic problems and domains in non-English languages, but (so far) there has been no broad and thorough working through of the process of lexical decomposition right down to level of semantic primes. Given the amount of intellectual time and energy needed to conduct such investigations they are unlikely to be forthcoming, in any numbers, in the immediate future.
Ewell and Adi did work that is almost what Goddard is anticipating.
The Readware system
Ewell and Adi looked at Latin and Arabic, Hebrew and Greek as a source for semantic primes. Only Arabic has a one-to-one correspondence between sounds and letters (in English and other languages sounds are ambiguous) and a ready made, clearly defined, root (prime)-word structure.
Ewell and Adi developed a meta-language based on correspondences they observed between Arabic letters and an underlying framework involving some theoretical constructions related to the delineation:
{ identity, manifestation, order }
They took these delineated constructions as one dimension of an ontological framework. This framework aligns with what Prueitt and his group have called “ecological affordances” related to how natural language is used by the individual brain/body system, embedding in a social system. Stratified theory indicate several levels of physical organization where ecological affordances are found.
The term “affordance” is new to Ewell and Adi, but they see that the BCNGroup has adopted a well-established term from a significant science literature, including cognitive quantum neuroscience and ecological psychology. Moreover, Prueitt has established a notational framework that ties together both discrete forms, Ontology referential bases or Orbs, of data encoding and continuum forms of mathematics where spectrum process is possible.
The Readware meta-language is like Arabic and patterned on Arabic though it cannot be called Arabic.
Ewell and Adi provide evidence for the universality of a set of subject-indicators (more than 2000 of them) indicated by the presence in spoken language of patterns of these primes. The BCNGroup calls these patterns “semantic roots” and conjecture that they are language independent.
Ewell and Adi created methods and tools for repeating experiments with any expression in English, German or French.
Given minimal resources, in the context of a National Project or agency special project, the combined team quickly could show how these methods and tools work for Arabic, Japanese and Russian.
An existing product, with German and English lexicons installed, suggests universality, at the substructural ontology level.
Anyone can use a word from one language to identify exponents of the word's reference (concept) in the other. Use any word.
Anyone can do this with a on-line tool.
Use: http://www.readware.com/rwSQp.htm
For example, enter "Bundes" without the quotes and query about German industry or economy or recent news in English. Anyone will see that it will identify German words that are exponents of the English word-concepts used.
In a special project, the combined team would provide to a small group of researchers a complete universal analytical infrastructure upon which the researchers can wring the sense out of any text or message, no matter what the language. This group can then deliver to the agencies a set of tutorials that discuss the underlying theory and the nature of results that have been found using open source text, from real time harvest of political discourse weblogs, or other source of real time discourse. This can be done within three months, with a team of 5 to 10 primary researchers working in either a closed environment or an open environment.
Any sort of analytical operation or function and any sort of inference engine can be added to the architecture.
What is now possible
The integrated architecture, between Readware and Orbs, is oriented to
the use of mathematical functions and fast analytical operations. This means that the notational work
completed by Prueitt and called differential and formative ontology can use any
latent semantic technology to encode new sets of semantic roots. From these new sets, one can create very
small topological covers that act as nets seeking specific types of social
discourse. These sets, and the Orb
sorting and retrieval engine can be parallel zed to process all text posted on
the Internet. This can be done within
three months.
The suggested encoding of resources into the very simple Orb data-encoding format is straightforward and could be done within a few weeks. The resulting system for analysis of the social discourse can then easily fit on a PocketPC, and run without any operating system dependencies except for file open and file close.
At this point, one would have an un-encumbered set of analytic tools. Unlike the Oracle database, and J-Boss based tools we see in the J-39 system, the Orb-encoding of the Readware letter semantics would be easy to use by anyone, without the encumbrance of software programmers and database designers.
As Prueitt has suggested to Mary Ann, at the agency, the agency could use our substructural ontology as a means to establish the presence of genuine communications between members of terrorist cells. Nothing like this exists in service, at least not outside a very small and closed group.
Ewell and Adi have classified about 2000 root forms -- a little more. They planned for 4000 and do calculate empty containers for 4000 so that new semantic roots can be added on the fly. These are hash table containers. The integrated system would replace the hash table with a key-less hash table, for reasons that can be discussed privately.
This information base is easily encoded into an Orb having less than 2K in memory requirements, a true “periodic table”. The Orb software is less than 400K and yet can address arbitrary size files systems. The compression of real time data flows into Orb constructions is fractal in nature, and has zero complexity in the limiting distribution. This implies that a five-minute slice of all Internet discourse can be encoded into an Orb having total computer memory requirements less that 10 Megs. These Orb constructions can be separated from the software and sent as simple ASCII files.
The Orb arithmetic allows the combination of Orb constructions with one pass over the two memories. The so called associative memories, common in the artificial neural network programs, can be defined with Orb constructions, called Referential information base (Rib) “lines”, as the “associated” elements. For tutorials on these methods see the URL [1] .
Some key theoretical consideration
The idea of whether each language distributes prime roots equally well can be separated from the conjecture that a set of universal semantic roots exists or not. The correspondence of prime roots to aggregations of substructural ontology can also be investigated independent of the conjecture on universality at the prime root level. Some languages may have a different set of semantic roots, which share universality in a common substructural ontology. These things are to be discovered in an objective fashion, much like the discovery of the physical chemistry periodic table.
The fact that all things under the sun can be described with concepts that are universally understood in any language is the significant factor. The key is “potential description”.
While cultural differences do exist, it is plain they can be observed and therefore readily annotated in the record. Ewell and Adi found that it was not necessary to find terms for every primary concept, before implementing a system of text analysis. A certain number of words linked to concepts is sufficient if one is attempting to find where and when some significant communication between members of a group is occurring.
Ewell and Adi did not study what was sufficient as a “measurement net”. We understand the importance of tasks like the automated identification of significant communication.
Perhaps the input stream of data is from a web harvest of real time Arabic messages expressed in the poetic version of the Terrorist “chatter”.
Prueitt’s term, “measurement set” is excellent, and the topological logics developed in the former Soviet Union seem entirely appropriate to the task of real time measurement of the social discourse. These topological logics, related to quasi-axiomatic theory, are notationally well developed by Prueitt and are implemented in his Orb software.
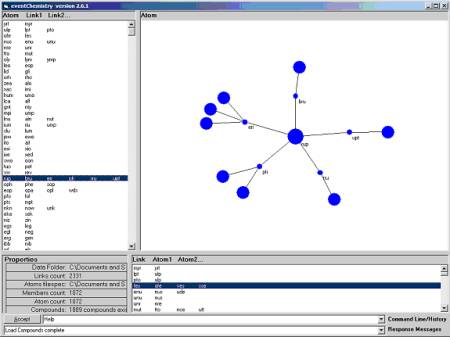
One of the semantic roots, with the underlying substructural ontology exposed
Could there be measurement sets, of semantic roots, with only twenty elements? Sixty? Ewell believes it is far more, at least into the hundreds-- probably into the thousands. There are some examples for this. Chinese children must learn about 6000 Chinese symbols (word roots) before getting out of grade school. Western children need a vocabulary of roughly 5000 words. High-school students need 8-10 thousand words.
The operational concept we speak about is that of a descriptive cover, and with that descriptive cover we see that you are able to move into these Orb based “topological covers” by subject matter indicators.
Ewell and Adi has found this notion of topological cover over the social discourse to be very attractive.
Even without such formal constructions, Ewell and Adi found interesting results. They did not find French representations (modern terms) for all of the prime concepts we had identified, only a little more than half. They are sure that the French have nearly all of them though they continue calling some things by outrageous constructions.
Ewell and Adi found that German is a very organized language that has carefully included all of them, as has English. Perhaps the differential use of descriptive covers, where the subject matter indications, what we call semantic roots, are Orb encoded substructural primitives, would allow linguistics to makes sense of our early findings about the distribution of semantic roots.
In both theory and practice, Ewell and Adi find these semantic roots in any language. They had already shown how ancient languages gave us the primary root forms of words that modern languages have greatly embellished upon, but that (at least in the case of Arabic)
For the study by Ewell and Adi, the Arabic cultural affordance has not subtracted or added one new element to either the substructural ontology or the semantic roots in more than 3000 years.
Arabic represented the most complete and coherent set to Ewell and Adi. But they are just beginning to explore the substructural ontology that Prueitt has conjectured as providing a commonality between all human language.