Preface
Revised May 24, 2006
Foundations 2007
“Current computer science operates with models of
information networking, and databasing that were conceived in the mainframe era
and cannot serve the needs of a truly connected world.
Designing the Future of
Information, Harbor Research Inc
Section 2: Second School Principles
Section
3: The role of pragmatism
Section 1: Preliminary notes
In
this book, a specific information architecture is outlined from a mixture of
complex systems theory and knowledge representation theory. A strong attempt is made to make a principled
grounding in the natural sciences.
It
is with respect and appreciation that we identify an alternative to the
semantic web and artificial intelligence disciplines, as classically envisioned
by scholars like Jim Hendler [1]. We call the alternative the second school of
semantic science and contrast this with the first school of semantic
science. The first school does not make
itself available to the concerns of leading edge neuroscience, biology or the social
sciences, staying firmly anchored in scientific reductionism. This is a criticism, but we feel that the
criticism is valid, objective and has supporting evidence. However, we are more interested in revealing
the second school viewpoint.
The
second school uncovers an information paradigm that is human centric. It preserves many of the engineered aspects
of current information technology. The
second school recognizes that knowledge of how and why things occur is critical
to many modern activities. It
recognizes that the current intellectual activity does not focus often on the
how and why.
Statistical
knowledge helps to define some envelopes within which things normally
occur. The questions to who, what and
where are given answers. However a
discrete pathway, containing states and transition between states, is more
descriptive of phenomenon such as gene expression or cell signaling [2].
[3] Gene expression research is one area where
ontological mediated science is beginning to make transitions from artificial intelligence
to something unexpected [4]
[5]. The limitations of statistical approaches
and the limitations to artificial intelligence are different, but in the
viewpoint that I am describing they both take paths away from understanding the
how and the why.
The
second school suggests that social expression is as complex as gene and cell
expression. All of these expressions of
nature are part of the study within the principles of the second school. Properly understanding the second school’s
viewpoint on complexity requires recognition about the limitations to the first
school. Once this recognition is fully
in place, then the second school builds on the existing technology through
simplification and through the introduction of a specific set of principles.
The
second school principles model natural process is being “sometimes”
under-determined, with respect to deterministic causes. The natural processes such as decisions made
by living systems seem to not only follow Newtonian laws but some other set of
laws. The model requires a theory of
stratification and emergence since we feel that the beginning of emergence is
where a high degree of non-deterministic reality can manifest. This issue of emergence is common in the
chapters to follow.
A
fundamental principle of the second school has to do with conjectured
non-algorithm aspects to these decision events. Sir Roger Penrose is not the only scholar who talks about
non-algorithmic reality. For some
reason, it is as if one has to start out showing that the assertion of
“everything is algorithmic” is a false assertion. Francis Crick certainly makes this assertion in “The Amazing
Hypothesis”. Accepting the second
school principle is consistent with the assertion that artificial intelligence
is a mythology and that this heavily funded academic discipline has produced a
lot of poor scholarship. This poor
scholarship has been seen to feed upon itself, producing a perceived
illegitimacy to many aspects of “science”, particularly information
science. In technology based on the
second school viewpoint, we place an emphasis on having a human in the
loop.
What
does it mean to have information science be centered on the human being and not
on the technology?
In
the second school viewpoint, the human is (to be) supported by process and
structural standards in developing information and encoding information into an
ontological model. [6] The ontological model is something that will
be a common focus to second school discussions. We feel that Hilbert mathematics, the advanced mathematics in
physics, has a limitation that is only fully appreciated when the second school
viewpoint is examined. In particular we
suggest that introspection about internal feeling of self, that has so far been
separated from mainstream science, can guide the development of new category
theory, and from this category theory some new formalism based on category
theory and not based on number. This
will not be easy, for many reasons.
Our
goal is to move the activity of science so that taxonomical, ontological and
mathematical models are more easily interfaced, and mathematics is not over
used [7]. The issues are not beyond easy
comprehension, and require a specific background in literatures. There are several ways to approach this
literature.
A
discussion of the history of bio-mathematics could be developed at this point,
but we defer this discussion. The key
point that would be extended is that classical mathematics does not have the
same level of success with biological functions as it does with engineered
structures. Acknowledging this key
point will be critical if science, and society, is to move information science
in a new direction. In the text to
follow, the reader will see that the new direction merges mysticism with
science by making corrections to both disciplines.
For
many scientists, the non-formalizability of common everyday activity is a
given. Certainly one cannot point to
formal systems with which everyday activity can be modeled. Yes, in specific cases, and within specific
boundaries one can model, with formal methods, everyday activity. But these models are not flexible, and they
certainly do not exhibit the types of emergent behavior, like the behavior of
thinking, that we experience with great familiarity. The spiritual expression seems remote to the current
materialism.
It
is clear and simple to state that formal models using first order logic do not
provide an adequate replacement for human awareness and reasoning. Web ontology language, for example, provides
something that works, kind of, in some situations; but these formal methods
have a number of specific problems. I
mention web ontology language [8]
even though many people have not heard of this. I will state here for clarity that my criticism of the web ontology
language work product is grounded in a detailed history. Again; however, this criticism is not the
focus I wish to make now.
We
can state the obvious. In everyday
activities, human being and communities localize (real) ontology
situationally. This localization occurs
through real physical processes that are supporting human awareness and
cognition. The second school brings a
simple representational technology to mirror these everyday activities. We do not call this “ontology” but rather we
call it ontological modeling. The
second school has revealed a technology standard [9]
that is based on the notion that symbols reference concepts and that our human
concepts about ontology might be referenced using symbols that emerge as part
of human use patterns. I will try to be
clearer about this as we move further into second school thought. An ontological model is a representation of
reality via a set of concepts.
In
theory ontological models [10]
may be used by members of a community to encode new pieces of structured
information into bit patterns that are compact, easily manipulated and can be
visualized on a computer screen. Like
words into grammar, the elements of an ontology use symbols to annotate concept
indicators. The representation can be
in the form of the W3C standard, a standard that uses a triple having the form
< subject, verb, predicate>,
but
the W3C standard is only one form of ontological modeling [11].
The
other well-known standard is the topic map standard. [12] I will not discuss topic maps here, simply
because the history to far to complicated and the basis for not allowing topic
maps to be the leading standard are too difficult to examine. The position I take is that the markets
choose incorrectly. If we were looking
for the best tools for modeling complex expression such as gene, cell or social
expression we need topic maps and the “n”-ary representation presented in the
notational paper, Prueitt 2002. [13]
The
specific problems with the W3C standard can be listed, starting with the standard’s
assertion that class structure be defined precisely. This assertion forces symbol systems to fix formal semantics and
in this way to create formal ontology that is not the best model of natural
ontology. Categories of processes
cannot be modeled with this assertion in play.
The list would also include the assertion that the resource description
framework, on which the W3C standard depends, is sufficient to represent any
type of human knowledge. The list would
include the W3C’s dedicated professional support of a community of “knowledge
engineers” who feel that they can encode everyone else’s knowledge but do not
understand anything about biology or psychology and often nothing about the
foundations of mathematics. Finally,
the list would include the assertion that web ontology can infer new
information in a way that is general and similar to the cognitive awareness of
humans. This last assertion is the
assertion made by the artificial intelligence discipline.
In
the chapters that follow we make the case that there will not ever be machines
made of abstraction that are self-aware.
We make this case by looking at the nature of abstraction, and the
biological processes that are necessary for thinking.
In
work being developed from second school design elements, the manipulation of
ontological models will be done via visual elements that correspond to the
invariant aspects of experience as realized by humans. How one judges knowledge about “invariant
aspects of experience” is by following accepted scientific peer review,
modified by new methodology being synthesized from spiritual practice.
We
hold that those who have intimate knowledge of a specific phenomenon will best
develop ontological models about that specific phenomenon. For example biological scientists should not
have to learn the rules of computer coding to develop and use information
observed in biological laboratory experiments.
The second school technology allows direct development of symbol systems
by simplifying both the underlying data structure and the operating
environments. [14] The optimal
underlying data structure is an “n”-ary,
< r, a(1), a(2), . . . a(n) >
encoded
using hash tables. In our proposed
“.vir” subnet of the his underlying structure is managed without any software
dependencies using the very basic computer processes. The operating environment uses a type of category management
based on stratification (to be discussed later in the book).
These
models can be explicit, and how these explicit models are represented is also
addressed a bit later in this chapter.
Semantic extraction technology will be discussed first. We have to first clear the air from the
misuse of words by the knowledge engineering and artificial intelligence
communities. The issue of misleading
concepts has to be examined. I have
used the term “polemic” to mean a mythology that is specifically designed to
not encourage further examination or analysis.
Semantic extraction is misnamed.
The second school claims that this misnaming creates a polemical
structure that improperly elevates the notions of artificial intelligence while
disallowing a critical examination of what the full nature of “meaning”
is. What these well-known techniques
and algorithms do is to discover structural patterns, mostly based on
co-occurrence of words or phrases. The
“meaning” is then imposed using some type of taxonomy or web-ontology. But the “extraction” of meaning using these
techniques is incomplete and sometimes incorrect. “Semantic extraction” would be better called “structure
extraction”. The reason why the phase
“semantic extraction” is used is that the hyped up buzz phrase “semantic
extraction” has been rewarded with many grants and contracts. It is that simple.
In
fact, an entire class of technologies measures the presence of concepts using
subject matter indicators, such as the presence of word, stem or word phrase
co-occurrence patterns. Some leading
researchers regard semantic extraction as a generalized n-gram analysis [15]
and we agree that most of the best semantic extraction software is some type of
n-gram measurement with a set of heuristics defined over co-occurrence within
the windows of an n-gram [16]. N-grams can be generalized to most of the
methodologies developed in the extensive image understanding literatures. These literatures are well reviewed by Tapas
Kanungo [17].
Some
obvious technical comments are needed.
The n-gram does not have to be a linear contiguous measurement of
co-occurrence. As one of many
generalizations of n-grams, some structure/function relationship might be used
in the process of indicating information that may become knowledge if perceived
by humans. The fulfillment of a
function desired, or anticipated, by the environment is the same as the pure
concept of “semantics”. Meaning and
function are tied together by artificially imposing one community’s sense of
meaning. Thus the values of the
software vendors, which are very narrowly focused on their making money, over
ride the natural functions that communities in crisis need to access. Transactions are placed under the control of
that one community in a way that is not, up to now, transparent.
Service
Oriented Architecture [18]
has had the promise that lines of business will be facilities by a network of
routers that control to flow of information generated by requests for
services. This beautiful concept was
usurped by the US Federal CIO Council’s work in 1993 – the present on allowing
special interests to hard wire all procurement of services based on the nature
of the software programs. Similar fears
regarding the electrical process are facing us as we go into the 2006
Congressional elections. The solution
to this structural problems between the citizen and the government is
transparency and the type of personal knowledge operating systems that my group
has designed, and partially implemented.
The
independent observation of social discourse [19]
opens up the possibility of a neutral measurement of functions asked for and
received. For example, the grammar in
natural language might be used in the computing of knowledge
representations. The notion of “a
passage” might be extended to include theories of discourse where the
boundaries of passages are irregular [20]
[21]
[22]. Passages are then seen to be the expression
of the various elements of human expression.
More is to be said on a full generalization of n-gram measurement
later.
The
point is that, for many of the semantic extraction technologies, n-gram
analysis occurs after there is a measurement process. Consistent with second school viewpoint, the measurement process
should have human involvement as part of the real time situated activity
leading to situational models of complex phenomenon. The measurement of individual expression involves a full spectrum
of emotional, intellectual, cultural and spiritual realities. This is not what is occurring in artificial
intelligence or knowledge engineering disciplines. The second school viewpoint holds that without a non-controlled
real time involvement in measurement the phenomenon involved in normal response
behavior will not be captured. So with
academic and government supported research and development being somehow
pre-occupied; what might be done?
This
issue of what is to be done occupied me for two decades. The experiences I was fortunate to be
involved in gave me the background to understand a specific set of issues, but
the pre-occupation of the institutions providing academic jobs and
capitalization seemed to be overwhelming.
I personally and professional failed over and over. Over the years the broad outlines of a
solution emerged. At first the outline
of this solution was limited to what might be called the intellectual dimension
to human expression. Beginning in 2005
I began to see that human expression remains poorly modeled if the emotional,
economic, cultural and spiritual dimensions are not considered. This new understanding has been very
difficult to integrate with the hard realism of science for the sake of
commercialism and war fighting.
A
very simple to use “knowledge operating system” is needed. This system must be processor independent
and occupying less than 100k of code.
The system has to have an internal interface to humans, and an external
interface into the Internet. It must reside
on any device that has a computer chip inside.
The
first designs were focused on the use of sensors to bring information to the
human, provide a repository of subject indicators, and provide structural
information about common response patterns.
These designs were developed for application to fighting wars,
protecting commodity transport and creating service architectures for business
transactions. Clearly these
applications were skewing the underlying technology.
These
comments point out that the technology that has been developed by government,
business and the academy has not taken into account systems theory. What is
known about design and functionality of natural systems? Lines of business defined as XML based web
services between the federal government and commercial business establish
empires. These programs have created
advantages for a narrow type of economic transaction. No transparency on this service provision process is allowed
simply due to the practice being so widespread as to be “business as
usual”. What is dis-advantaged are
human values related to family, the individual owning of homes, and the
economic prosperity of individuals.
The
concept of a utility function may help my inadequate description of the nature
of the problem space we current face.
This concept is applied to models of processes that are largely
reducible to computer simulation. The
discipline of genetic algorithms is an academic study of the evolution of
computer simulations. [23]One
sees the utility function as an essential part of these simulations. But more broadly we see the utility function
as being the non-Newtonian guide to the evolution of natural systems. The point to my discussion about technology
being shaped by commercialism and scientific reductionism is that this
technology itself has become a utility function over our cultural and
individual expressions.
Let
me give a specific example. Dr Richard
Ballard has for several decades worked on a non-serializable knowledge coding
system. Several of his systems have
been developed and deployed under government contract. These systems are designed to help manage
government contracts in the area of national defense. The work solves certain types of problems but at core asserts a
set of social and cultural values that are skewed towards economic transactions
supporting war efforts. Ballard’s
contributions are only very partially published since his work has been part of
a proprietary process, to which he has shown dedication. Personal communications between he and
several members of our community have helped in the development of views about
how “semantic web” knowledge systems will work in the future. As my group and other groups work to achieve
success in our professional efforts, the utility function created by war
efforts has been shaping our work product.
Ballard’s
work is not the only contribution that is beyond n-gram technologies. Another member of the second school is Tom
Adi [24]. As does Ballard, Adi works with the notion
that sets of semantic primes exists and are composed into subject matter
indicators (during the process of generating language in normal everyday speech
and writing). The work of both Ballard
and Adi pointed me more clearly to the notion of generative data encoding. There is a generative progress involved in
creating systems that “do something” in the real world. The question had become, “what have our
technology systems been designed to do?”
Tom
Adi’s work was always focused on understanding the cultural and personal
aspects of human expression and thus has deep spiritual roots. Richard Ballard’s work has focused on
providing ownership over the intellectual property produces by a narrow range
of social expression. This work leaves
out the spiritual values and replaces these with a competitive reality where
ownership is essential.
A
range of consequences develops due to the patterns of economic
reinforcement. The drive to assist the
individual and communities move toward sustainable and resilient
ecosystems. The drive to achieve
spiritual qualities has to compete with a fierce measurement of utility driven
by commercialism. These facts are the
facts of our lives in 2007. These facts
are everywhere evident. Which drives
will win out and become the dominate social reality of the twenty first
century?
By
examining my own work during the period 1991 – 2004, one can see how effective
the utility functions have been.
Starting in 2001, differential ontology [25]
was directed at the production of knowledge representation from semantic
extraction techniques. The extraction
techniques develop co-occurrence patterns and these patterns are (in my
architecture) presented to the individual for manipulation. A support structure for development of
ontological models focused on the nature of individual human memory and
anticipation. But the underlying
motivation for the systems I was designing was to control commodity transport
worldwide. [26]
In
theory the focus of ontological model development becomes individually
centric. The individual is supported in
acquiring information that is relevant to real time situations. The general principles were that individuals
should be empowered to take control of personally defined information spaces. There were issues of course. The nature of human expression is shaped by
the means with which the expressions occur.
The powerful consumerism shaped by the American success is reinforced as
these models are used to control commodity transport. The utility function distorted my work product and limited what I
was able to achieve. Was my experience
unique to me? I do not think so.
Many
people see that consumerism is wasteful and has created specific classes of
imbalances. The principles that
motivated the development of my model for US Custom’s control over worldwide [27]
commodity transactions could be used to reduce waste in these transactions and
to decrease the imbalances to or cultural, economic and environmental
systems. But few in government were
interested.
Over
the past year, 2006, I have been more deeply involved in meditative practices
in several retreat resorts in Taos and Santa Fe, New Mexico. The full integration of the human soul has
been the subject of meditation practices for centuries. In retrospective, the approach I had been
taken regarding the use of categorization seemed incomplete. Being human centric should mean more than an
increased ability of the individual to be a successful consumer and war
fighter.
The
core issue seems to be how balances can be made between the various energy
centers of the human being. The
integrated self, made whole by meditative contemplation seems possible only
when the more aggressive drives subside.
On the other hand, the paradox remains as to what to do when there is
such an imbalance between those who have economic power and those who do
not. We will return to these issues
often in the “Foundations 2007” [28].
Semiotics
is a discipline that refers to a system of signs, such as natural
languages. In differential ontology,
signs may develop from an interaction between socially oriented knowledge
management and normal everyday activities.
This type of interaction depends on the development of instruments of
communication like normal language, but in addition to the normal mechanisms of
natural language there is a computational form. This form becomes part of a
symbol system reified by use as a communications tool involving more than one
person. The symbol system is managed
through the human interaction. The
individual symbols are each formal topics in the topic map.
In
chapter one we will talk more about the cognitive neuroscience that inspired
the full concept of differential ontology, and the “stratified architecture”
that makes it work. At present I can only suggest that in the near future,
humans will develop sign systems based on ontological models in a way similar
to how geometry and arithmetic was developed historically.
We
have come a long ways, in spite of obstacles. The first school is sidetracked
by the assumption that classical logic is sufficient in computing the
consequences of knowledge experiences in real situations. In part, they (and “we”) were lead into this
mistake by the success that Hilbert mathematics has had in physics and
astronomy.
The
primary difference between ontological models and mathematics is that with
ontological models the abstraction is more situationally focused. We may remember that physics and astronomy
deals strongly with “universals”.
However, living systems seem to have aspects that are not accounted for
by the universals of physics and astronomy.
This is interesting, and if correct this perception tells us about
science and also about life itself!
Imagine that!
Because
incompleteness, inconsistency and uncertain information are often important
properties of real biological processes, the focus on phenomenon is
complex. For example, decisions are
often made with uncertainty or informational incompleteness. In Chapter one we will look closer at the
notion of “coherence” and see why this misuse was almost unchallenged.
We
understand now where the open questions are located. The second school refers to most current “semantic extraction” as
a syntagmatic extraction, since a structural pattern is “all” that is found. The certainty of formalism like geometry and
arithmetic is found in the measurement of these structural patterns. There is no ambiguity in the results of this
measurement. But the measurement process itself can be flawed. The measurement
of structure, such as the concentrations of protein expressions at a specific
time by a specific biological system, can be incomplete or mismeasured.
Beyond
measurement issues are issues related to emergence of function. The measurement of the function of structure
is where uncertainty, not related to incomplete knowledge, occurs. With differential ontology the measurement
presents to human visual inspection those ontology signs and symbols that evoke
meaningful mental experiences. The
human is then allows, in real time, to make the categorical abstractions based
on human intuitions and cognitive abilities.
In
this way, the natural process of human induction is applied directly to the
output of computational processes mediated by structured information, taxonomy
and formal ontology. By leaving out the
formal inferencing, we present for human inspection sign systems that are
measuring precise patterns. The origin
of knowledge is then within the control of the human who uses the system. [29]
A
human experiences meaning. The
computational “meaning” extraction processes is not “from a human” but rather
from the organization of words in text.
We measure a transaction space that is not directly the space where
human thought is being developed and shared.
We hold that when we misuse language, use the word “semantic” when we
really should use the term “structure”, then we diminish the quality of the
technology that is produced. We make
mistakes because the misuse of language directs us into these mistakes.
Section 2: Second School Principles
The
second school finds bypasses to specific hard problems that have blocked
success in transitioning information technology to individual control. These bypasses produce a knowledge operating
system useful to individuals or communities.
We have been designing our knowledge operating system since 1998. The original design of KOS was made partially
public. [30] In making these public disclosures we were
acting in a way that is consistent with core principles, in particular the core
principle that all software IP will eventually be set aside. This
principle is based on a set of “optimality proofs” [31]
suggesting that computational technology must eventually be optimal and not
patentable. The current, 2006, details
of the technology designs are layered with a social philosophy being on top. [32] At the bottom is a process methodology for
starting with something fully specified.
That technology infrastructure is then expected to evolve in a natural
way. The knowledge sharing foundation concept was
first developed (2003) as a suggestion supporting the US intelligence agency
needs to develop information about event structure. [33]
Previous to this, a small group of scientists had talked, since 1991, about the
need for a curriculum, K – 12 and college, to support an advancement of
cultural understanding of the complexity of natural science. [34]
So one of the layers has an educational
grounding.
The
knowledge operating system can be as small as 17K and be independent of the usual
software platforms. The KOS develops a
referential base having a specific well know and standard format (essentially
topic maps) and this referential base can be large. [35]
When
a particular knowledge operating system has been provided structural
information, a measurement process and the visual interface to a human
perceptional system, then we create the basis for knowledge-based anticipation
of “what is next”. At this point six
classical Greek interrogatives; who what, where, when, how and why, are used to
produces both new human knowledge and to allow a greater sharing of this
knowledge. The technical means to
achieve this interrogative based information definition uses what I began in
2003 to call “general framework theory”.
[36]
We
believe that the nature of the structural information and the nature of the
transaction space for encapsulated digital objects will be accepted by the many
virtual communities such as Second Life [37]
. Structural information encoded as
generative digital objects provides control mechanisms for the individual.
The
key element of this potential acceptance is the second school principle that
separates push and pull advertising.
But
not all of the residents of Second Life are happy about the commercial gloss
that is starting to spread throughout the world. They argue that the appeal of these fantasy realms was that they
offer an escape from the uniformity of a globalized society. [38]
The
separation of push and pull information has the potential to transform many
kinds of social activity, from on line shopping to group collaboration within
virtual communities.
The
separation is made possible using several of the second school principles. In order to talk about these principles, we
need to introduce the technology movement called “SOA”. Service oriented architecture (SOA) began to
be a buzz phase in 2003 and 2004. Since
that time great effort has been to develop standards that reinforce the existing
centralized control over service definition.
Individual business powers saw that a repository of service access
points would change the status quo if services were merely competitive based on
consumer oriented outcome measures. We
observed that advertising is what keeps firmly rooted service providers in
market positions. We also observed that
the industry powers have a collaborative synergy that protects the concept of
centralized authority.
I
was living in Northern Virginia and attending government-sponsored meeting as
the interest in SOA began to ignite. It
was clear to me and to others that big business was working hard to not lose
the existing strong monopoly on government funding for services. However, SOA is a concept whose time had
come. I studied the emerging standards
and followed the discussions.
An
example of the business orientation of SOA is expressed in a recent advertising
for a web seminar on SOA
The
goal of a service-oriented architecture (SOA) is increased IT adaptability,
reduced cost of application development and maintenance, and better aligned IT
professionals and business users. But the ultimate benefit of an SOA is better
information. And better information benefits business users. Done right, SOA can help business users shift their focus
from merely running the business to maximizing the performance of their
business. Not only will they be able to lower infrastructure costs, they can
optimize their organization’s key assets – information, customers, and brand.
Literally
hundreds of IT companies are in competition to “deliver” SOA
transformations. However, it is
conjectured, that there are real deficits in how the concept of a service is
realized in any of the current leading SOA vendors.
The
“.vir” standards start out with the general systems theory notion of a
transaction space. The standard
recognizes that the transaction space has a manifestation in natural reality
and that any model of the transactions spaces is limited not only in the
initial form but as a consequence of the normal evolution of natural
systems. I am regarding the term “transaction”
to be appropriate in describing the exchanges between living systems in complex
ecosystems. [39]
The
strategy we have developed is to lay down a best of kind MUD (multiple user
domain) based on a long study of the 1988 DARPA MUD engine as realized in the
Palace virtual community system and the Manor virtual community system, as well
as the new system designs we see in Second Life. This work has been studied by several members of my close
associates, in particular Nathan Einwechter in Canada and Amnon Meyers in California. As of November 2006 we are awaiting
capitalization of OntologyStream Inc. [40]
VirtualTaos
has also been designed to use a specific selection of the SOA standards,
starting with the SOA Reference Model [41] A number of models describe how repositories
of information are to be created and how programs or individuals should best
interact with these repositories. Perhaps
the reader would reflect on what he or she observes about the competitive
marketplace of today. De-centralization
of service selection would change the utility function, creating service
information that was rated on objective community, ie consumer, measurement. Advertising per se would be reduced in
importance and would change to allow a measure of the truthfulness of the information. Oh my!
The
evolution of the concept of service-oriented architecture initially was focused
on bringing order to a de-centralized flow of goods and services. The notion was, and still is, that the many representations
of service potential should compete on a just in time delivery of these
representation in response to service request.
The service request drives the entire system, even if not
decentralized. The orchestration of a
selection is, in theory, totally managed automatically with no human
interaction in the real time.
As
the SOA architectures have become functional we see that the effort to hard
wire competitive advantage extended beyond the IT vendor to selected
collaborations with non IT service providers, further extending control over
services to the IT vendors. Nowhere is
this more obvious that in the education sector. Rather than get off into this discussion here, we simply give the
URL where the most advanced deployments of service oriented architecture into education
might be judged to be occurring. [42]
The
anticipatory architecture, suggested in grant proposals by myself to US
intelligence agencies in 2001 – 2004, uses syntagmatic expansion and contraction
mechanisms to tease out the response patterns that are anticipatory of
behavioral state transitions made by individual, economic and social
systems. The notion of anticipation has
not been developed in the SOA architectures, in spite of a number of standards
describing such things as “service discovery” and “service fulfillment orchestration”.
The
anticipatory technology’s principle technical innovation has to do with a
separation of the substance of information into two types of ingredients. One
type of informational substance is related to phenomena observed to be involved
in human memory [43]. The other
informational substance are those mechanisms, largely functional between the
frontal lobes and the limbic system [44],
involved in what Karl Pribram called “executive” control over mental event
formation [45].
The
second school’s formalization of this separation is inspired by a study of
cognitive neuroscience and related scientific domains like immunological
theory. The study of cognitive
neuroscience and immunological theory was part of my “early career” (1985 –
1995). Knowledge Foundations [46]
provides a look at this background. In Foundations, we address the technology
and architecture inspired by this early work.
The technology and architecture is informed by applied semiotics as
practiced in a particular Soviet era school of cybernetics [47]. In this “applied semiotics” school,
information primitives were derived from a set of invariances measured across
multiple instances. A system of symbols
arises that serve as control elements to computer assisted decision support
systems. This scientific work was
largely disrupted due to the collapse of the Soviet political and economic
systems in the late 1980s.
Many
core concepts are re-emerging as Soviet era science settles in other parts of
the world and finds lines of research, native to those other communities, which
are consistent with these core concepts.
If one looks carefully it is possible to see that in all parts of the
world general systems theory type work has been published for many decades.
One
could study human memory research to fully appreciate the theory underlying our
use of informational primitives and top down templates. However, one might also appeal to private
everyday experience. In common
experience we see invariants in our concepts of texture and color or emotional
responses. These invariants are part of
the experience we have as living human being.
The notion of an invariant across many instances seems to have always
been in my mind, but certainly my exposure starting in 1994 to the work of the
Soviet era cyberneticians [48]
intensified my focus on invariance as a means to identify “semantic
primitives”.
Cognitive
science proposes that the invariance that is experienced by a human mind is
aggregated into a physical memory store.
Direct experience subsets part, but not all, of these invariants in
response to perception of specific things.
In the biological processes supporting human awareness, the subsetting
process is constrained by anticipatory responses and images of achievement and
action [49]
.
How
does anticipatory technology compare with what we humans are familiar with in
everyday life?
Everyone
has direct experience with awareness, and experiences that come from the many
acts of communication with other humans.
In natural language, as in all other mental phenomenon that the human
mind shapes, abstractions are used to refer to the invariance found in real
experience. Examples of a system of
abstractions are the concept of a counting number and the concepts about
color. The concept of the counting
numbers is a particularity nice example of an abstract upper ontology. The upper abstract concepts should have the
property that they are unchanged by use.
This independence from situational use is one property of arithmetic
that gives us commerce and the engineering sciences.
Given
a specific biological entity, a set of top down anticipatory templates will
have been developed over a period of time.
These templates model how events are connected together. Part of the mechanisms will be genetic and
part will be specific to experience.
How these mechanisms work is highly complex and is not yet fully
understood as a matter of objective science.
The
first ontological descriptions of behavioral patterns will be
simplifications. The distance that has separated
IT from the core behavioral sciences is a profound problem. We are not given funding support to bridge
this gap, for complex reasons. It is
simply beyond my personal ability to support this assertion in a scholarly
fashion, and I apologize for this.
We
could look at biologically motivated models of neural function. The ontological template is certainly
reminiscent of the top down templates that Stephen Grossberg developed,
starting in the late 1960s, as part of his mathematical theory of human
perception [50]. The top down template in Grossberg’s
architecture has been used in many types of applications and has been subject
of thousands of research articles. The
basic concept is that a basin of attraction of a continuum dynamical system
develops through iterative adjustments to a mathematical model, in Hilbert
space mathematics; resulting in what is called “reinforcement learning”. Parallels to reinforcement learning as
studied by cognitive neuroscience have been reviewed by hundreds of major
research articles. This research
literature is vast, and we will allow the reader to look into this or not,
depending on the reader’s level of technical background in Hilbert type
mathematics and in the relevant sciences.
Ontology
templates have a different nature. They
are the explicit side of a dualism between explicit and implicit
representations of subject indicators.
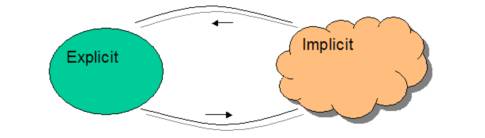
Figure 1: Fundamental diagram for
differential ontologystream
By
“implicit ontology” we mean an attractor neural network system of one to the
variations of latent semantic indexing or rule based semantic extraction
systems. By “explicit ontology” we mean
a bag of ordered triples
{ < a , r, b > }
where
a and b are locations and r is a relational type, organized into a graph
structure and perhaps accompanied by logic.
Our
templates have explicit forms and these forms can be part of additional
technology such as colored Petri nets [51]. In my PhD thesis (1988), I developed several
chapters on what I called homology between discrete dynamical systems and
neural network models of the type that Grossberg invented. Later, in 2000, I made the obvious
connection between discrete formalism state transitions and the state
transitions seen in neural network models.
This lead to the concept that one might be able to have both a discrete
formalism, like a Petri net or like an ontology defined set of symbols with
state transitions defined explicitly, and a continuum formalism like a neural
network. Several technical means were
developed to explore how to extract the discrete formalism involved in subject
matter indication using the SAIC owned patented Latent Semantic Index
technology [52].
My
work in 2005 has focused on using human reification of the results of several
commercial semantic extraction systems, including those sold by Convera,
AeroText, MITi, and Applied Technical Systems.
This work is discussed in the context of a Global Information Framework
based on what I called the differential ontology framework (DOF) [53].
Ontological
models extend the modeling function of Hilbert mathematics to formalism that
serves to unify social construction about objects of inquiry into an objective
set of concept representations. But,
unlike Hilbert mathematics, there is no demand that universal truth is established
through the formalism itself.
Situational truth is established only via the usefulness that these
constructions find as human communities use ontology to serve the community or
individual purposes. Truth that extends
beyond single instances is available within the context of reified standards,
but ontological modeling should always acknowledge the possibility that new
categories will arise.
There
is a separate issue related to the nature of logical coherence. Logical coherence has always been loosely
defined based on a sense of sufficiency in reasoning, i.e., what is considered
rational. Rationality, in spite of its
value, breaks down at a number of places.
First is the problem that other minds do not always agree. This problem can sometimes lead to extreme
problems. The fact is; however, that
the underlying physics of coherence is what gives the sense of rationality a
firm basis. The brain requires phase
coherence in the electromagnetic spectrum in order to support perception and
cognition. [54] The fact is also that in physical coherence
we have phenomenon such as C-tuning forks and D-tuning forks. A D-tuning fork does not make a C tuning
fork ring.
The
core difference between the first school and the second school is that the
first school assumes that Hilbert mathematics is the ultimate representation of
truth, and that the imposition of first order predicate logic brings the
ultimate truth of Hilbert mathematical reality to the ontology of social
processes. At core this is the
“ontological commitment” made by Cyc Corporation [55],
and the history of this corporation is one key to understanding the limitations
of the Semantic Web concept produced by the W3C standards body. The second school suggests that natural
science shows this first school’s ontological commitment to be a profound
error. The second school also suggests
that when one gives up this error, one is able to define new technology that is
both human centric and easy to use.
Differential
ontology framework does in fact set up an anticipatory technology.
In
our architecture, an encoding of templates and representation of invariance is
achieved via a type of category theory and set theoretical operations called
convolutions. Our formative category
theory is used in the formation of behavioral atoms and periodic tables related
to specific objects of investigation.
The elementary operations that we defined using set theory is performed
on a hash table like, key-less hash table, ontology persistence construction
called an Orb (Ontology referential base).
Referential ontology is regarded as a set of concepts, and can be
translated into standard RDF (Resource Descriptive Framework) [56].
We
conjecture that in the near future, ontological model based templates will be
designed, by scientists or domain experts, to model behavior expressed in the “.vir”
subnet of the Internet. This is fully
consistent with a new OASIS standard specification called Business Centric
Methodology. [57] In fact,
the BCM standard is more general that what is needed to provide services to
business processes. A derivative
standard is being outlined with the name “Process Centric Service Methodology”. The two key innovations in the BCM standard
is the notion of service blueprints, and provide a formative framework and
human choice points that allow humans to choose between blueprints. This new standard and related standards is
discussed more fully in chapter one.
In
any natural situation, the function of emerging composites is formative within
a specific template or between templates or categories of templates [58]. Opening up the interpretation of structure
creates something for the human to do and the human will do this very well. How well future ontological models are
defined depends on human individuals knowing that reality has situational
features. Having a handle on these
situational features is vital if one is to understand as much as one can about
something like the intentionality of living systems [59].
The
fact that categories drift and new categories emerge, unexpectedly, is the key
to future ontology specifications.
Section 3: The role of
pragmatism
Perhaps
nowhere is the difference between the first and second schools more apparent
than on the issue of pragmatism. The
second school holds that meaning has a pragmatic axis. This axis exists only in
a real situation.
Oddly
enough, human awareness also exists only in the present moment. Natural situations occur only in real
time. Abstraction is separated from
this pragmatic axis and sits in a time independent fashion. Meaning is often indicated by an abstraction
but it takes a perceptual experience to realize the full meaning. The abstraction in an ontological model,
like text on a page in a book, evokes mental experience. In normal social discourse, this evocation
occurs only in a non-abstract situation; i.e., in a pragmatic axis to reality
(in the moment). The first school has
been busy developing a world where the ontological specification occurs by
computer science professionals. Up to a point this work is important and
useful, but the true limitations to standardizing our representation of natural
processes must be acknowledged.
The
distinction between what is experienced and what is abstracted into natural
language or formal constructions is the key to a Human-centric Information
Production (HIP) paradigm. HIP is not
free. The use of categorical abstractions
and anticipatory templates by users requires an educational background that is
different from that which most college graduates receive. We have to then take up the question of our
educational system. We have asked
questions about what should be in a K-12 curriculum designed to make knowledge
operating systems as familiar as natural language is today.
The
second school follows the path of scientific realism. While we acknowledge the utility of scientific reductionism, we
also acknowledge the limitations that are created when reductionism is
practiced as if a religion. We suggest
that there are good reasons why science and mathematics is ignored and rejected
by the majority of students. Science
and mathematics have become a pathway to a narrow profession, not necessarily
to an increase in personal knowledge.
While it is true that the science and mathematics professions product
economic value within our social system, it is also true that the economic engines
that are being created are damaging our environment and perhaps the social
structure. It need not be this
way. We must look at nature and see it
for what it is and not require that it fit within our expectations. The second school is a bridge to the
knowledge science. We predict that the
science of knowledge systems is to be built based on scientific realism.
We
envision that the use of anticipatory technology will result in the formation
of a world wide anticipatory web of activity.
Different from the mainstream notions of a “semantic web”, the
anticipatory web will arise from the activity of many individual humans using
computers to provide structural information about aspects of real time,
experienced, reality through a measurement of relevant data. The core issue is the separation of a
reasoning component from a visualization and computational component.
Tim
Berners Lee properly addresses this core issue in a 1998 paper [60]
on “The Semantic Web as a language of logic.
A
knowledge representation system must have the following properties:
1. It must have a reasonably compact syntax.
2. It must have a well defined semantics so that one can say
precisely what is being represented.
3. It must have sufficient expressive power to represent
human knowledge.
4. It must have an efficient, powerful, and understandable
reasoning mechanism
5. It must be usable to build large knowledge bases.
It has
proved difficult, however, to achieve the third and fourth properties
simultaneously.
The semantic web goal is to be a unifying system which will (like the web
for human communication) be as un-restraining as possible so that the
complexity of reality can be described. Therefore item 3 becomes essential.
This can be achieved by dropping 4 - or the parts of item 4 which conflict with
3, notably a single, efficient reasoning system. “
Tim Berners Lee’s remarks are consistent with a
school of thought that points out the limitations that have been seen in formal
systems. But his insight in to the limitations
of formal systems is not complete. He
does not question whether it is possible, under any circumstance, to have sufficient expressive power to represent human
knowledge. An extensive scholarly
literature exists about these limitations (see Chapter 2, Foundations).
Beginning in 2005, the BCNGroup (Behavioral
Computational Neuroscience Group) declared that Semantic Web technology falls
into two major schools of thought:
a)
The First School of Semantic Science stipulates that ontology supports common
sense reasoning with the imposition of constraint logics like OIL
(Ontology Inference Layer for RDF – Resource Description Framework).
b)
The Second School of Semantic Science stipulates that ontology enables
knowledge sharing, which can best occur with minimal dependency on
constraint logics and inferences based completely on algorithms.
One school holds onto the polemics of
artificial intelligence by acting as if computer inference is more desirable
than machine to human interfaces. This
school brings us software systems, like Protégé [61]
and Jena [62]. Very few professional computer scientists
can get these software systems to work, and the possibility that average
individuals will agree with the assertions of Protégé and Jena are zero. It is quite easy to point out how ridicules
these assertions sometimes are. As a
general rule confirmed by community experience, one gives up one’s human
centric design principles in order to develop a working software system. The first school also participates in an all
or none polemic where one is expected to completely accept the standards-based
assumptions. The first school advocates
tend to ignore those who do not agree.
Proponents of the first school often demonize those who will not buy
into the standard. This behavior is
reinforced by the control over the funding mechanisms that the first school has
enjoyed. The reader is reminded that
the author understands that his criticisms of the system have been hard to
justify. The situation is both complex
and filled with difficulties having cultural roots.
We
can make this very simple. The second
school rejects the notion, in principle, that one can substitute computational
inference for human reasoning and the human experience of meaning.
We
can be polite to the old ladies. This
rejection does not give up advanced computational algorithms such as those
found in what is currently called “semantic extraction”. Algorithms such as neural architecture
inspired pattern extraction and categorization, latent semantic indexing and
probabilistic latent semantic analysis, are extremely useful in developing
computational instrumentation that measures invariance and patterns of
invariance. The algorithms produce
subject matter indicators and these indicators are used in a methodology
developed within the second school. So
we build on what is correct about what we now have.
In
the second school paradigm, the individual will produce information in a
fashion that allows both a pre-structuring of response and communication channels
and the creative input in real time.
This human centric approach sets aside the unreasonable desire for an
efficient, powerful, and understandable reasoning mechanism. In making this choice we move away from an
often very difficult technical discussion about logic constraint language
standards and consistency checking. We
move toward an analysis about knowledge sharing that is often not at all about
the limitations of computer science and formal constructions. We are able to speak in a plain language
about the social and individual experiential aspects to knowledge sharing
within communities of practice. The
discussion shifts from dysfunctional IT to social theory, human factors and
knowledge management issues.
No
one can tell what social transformation will occur co-incident with the
appearance of low cost and easy to use to use anticipatory technology. Certainly the advent of the second science
of semantic science will transform the criterion that has controlled federal
and private funding of semantic web activity.
This transformation will mark the end of a period of time in which
science has been held back by religious type beliefs. Oddly, the religion of reductionism is what separates theories of
intelligent design from mainstream funded science. By respecting, but putting aside, the polemics that come from
this separation, we are allowed to regard human introspection as a proper
subject of scientific investigation.
We
restate that the role of the individual is critical in the formation of
constructions relied on by anticipatory web mechanisms. These constructions do
share properties related to the origin of natural language and properties from
the induction of logico-mathematical formalism. These properties suggest a way to overcome the specific types of
limitations that computer science inherits from the foundations of
mathematics. So one does not avoid the
need to understand the history of logic, and the natural science related to
mental events. In fact the second
school elevates the natural sciences and the history of formal constructions
such as arithmetic and mathematics.
Human-centric information processing has deep roots in the history of
science. We celebrate this
history.
HIP
requires a human reification of sets of subject matter indicators. This reification process imputes semantics
through an induction of real mental events as experienced by humans. The human, not the computer program, is given
responsibility to understand the emerging situation. The human is helped without hindering. The human is given the responsibility to decide, and with this
given responsibility we shift the evolution of a culture that has more and more
hidden its moral responsibilities in confusion and legal complexity.
In
our technology the set of induced constructions encode knowledge of objects of investigation
into structural ontology. The
structural ontology is open to modification while being used in everyday
activity. As in the origin of natural
language, the encoding of structural information into explicit form is an
origin of computable mechanisms that support and extend social use
patterns. How a specific social use
pattern persists as part of everyday life is a question we address with event chemistry. As in physical chemistry, event chemistry
assumes all events are composed from a small set of primitives. The mental events are experienced as single
coherent phenomenon, but each is composed of semantic primes. In physical chemistry the primes are in each
case from a single set of physical atoms.
There is universality to the set of atoms. Think about this for a moment!
Why should mental events be different, in this respect, than chemical
events? Yes, mental events may have
constraints and causes that are not governed by ONLY the conservation laws that
appear to fully constrain physical chemicals.
The nature of life is not a closed scientific question.
In
semantic space the event structures are more difficult to determine, and may
not be as simple as with physical chemistry.
We do not know as yet how to map between semantic primitive space and
the experience of meaning by humans living within everyday activities. But who do we need to get permission from to
explore these issues openly?
In
the several semantic extraction systems that we have looked at, we find
slightly different sets of primitives.
But a set of primitives is always there, implicitly or explicitly.
In
some cases, the primitives are found as part of the process of using the
software. In some cases, notably the Adi
and Sowa systems, the primitives are specified. How semantic primes are used in each case can be discussed only
after some common notational machinery is developed and accepted as language
between experts. Our notational paper
on ontological referential bases [63]
offers such a language. It should be
noted that this language is not first order predict logic with lots of symbols
that are difficult to comprehend. We
use very simple set theory and well referenced general systems theory. This foundation is very simple.
In
future systems, based on differential ontology, we expect to use an extension
of Mill’s logic and QSAR (qualitative structure function relationship) analysis
to instrument an inferential entailment defined on produced ontological model states. The result should also extend a classical
state transition simulation technology called colored Petri nets [64]. Behavioral analysis that is global in nature
is then immediately possible.
This
work extends some principles in current chemical science to a set of principles
in an emerging science of complex systems whose regularity within context can
be recognized and used as informational products produced from computational
semiotic systems.
Machine
encoded structural ontologies persist by encoding structural information in the
form of very simple graph constructions.
These constructions can be expressed as Topic Maps, or in the W3C’s Web
Ontology Language (OWL) standard, on in other data encoding mechanisms that
have higher efficiencies related to storage and transmission. However, standard ontologies are most
generally manually developed. There is
no formative process, except perhaps has hidden in the professional journals of
knowledge engineers and artificial intelligence scientists. The Orb ontologies, see Appendix B, are
semi-manually developed since some part of the ontology is produced in a
subsetting query to manually developed ontology. But a considerable part of the Orb is a measurement of co-occurrence
patterns. The co-occurrence is often
not merely of proximity of words to each others, since the measurement may
first reduce text to an ordered set of stems or other indicators of the
presence of primitives. The Adi
structural ontology is the clearest example of the reduction of text to a
measurement of semantic primitives, but Ballard’s and Sowa’s work has similar
reductions. The measurement for
semantic primitive indicators results in an aggregation of indicators into an
indicator about a higher-level construct; such as a concept. Applied Technical System’s NdCore semantic
extraction system, as well as the Entrieva semantic extract system, has this
aggregation function.
The
aggregation of semantic primitive indicators into concept indicators is a key element
of all semantic extraction systems.
This is observed in the Orb notational paper (Prueitt 2005) and is the
basis for event chemistry analysis of structure/function between semantic
primitive indicators and the concept indicators.
However,
it is critical to now make a reference to the notion of stratification. In “Knowledge Foundations” [65]
one finds the physical theory that grounds the claim that human memory arises
as an emergence of localized coherence.
Several chapters focuses on evidence from natural science that a
stratification of physical processes is available and enforced on all physical
processes, including those that support human cognition. This claim is addressed in a physical
science foundation to a new anticipatory and knowledge sharing technology that
I have suggested.
Figure 2: An early control interface
over an ontology referential base
A
“formative” model of mental event formation is suggested by physical
science. The model is transferred to a
technology for formative ontology. In
the anticipatory web, information is created by putting together ingredients,
within the constraints of a real time situation, with the aid of direct human
involvement. The information is encoded
as sets of concepts, often with various subject mater indicators that allow the
user to create computable subsetting, or filtering, programs that gather
together all information necessary to have localized a clear, complete and
consistent (the 3Cs) representation of some object of investigation.
In
the differential ontology framework (referred to as “DOF”) the subsetted set of
concept representations produces a visualizable, small, data encoded
construction called an instance-scoped ontology individual (referred to as
is-OI). The is-OI is evocative of a
human mental event, and when perceived produces an induction of meaning from
the availability of human tacit knowledge and from the set of structurally
encoded concept representations.
Within
the new technology, anticipatory mechanisms natural to human intelligence are
given additional support via a set of computer-encoded invariance and the
templates. The anticipatory technology
does not treat the computer, or computer networks, as being the origin of
intelligence. The computer is regarded
merely a measurement device.
In
an anticipatory web the nature of computing is placed into a context where
natural science is able to make explicit the limitations that computers have,
and not over step these limitations.
This recognition about limitations has many benefits. First, a mature view of information science
is taken.
The
maturity is well deserved. Unlike the
first school, we do not assume that computer programs can know anything. We acknowledge that the computer is not
aware of information and cannot verify if the information is appropriate. The importance of individual humans working
on every day activities is recognized.
One
of the surprises coming from anticipatory technology has to do with some specific
innovations that simplify data management through a clear understanding about
the relationship between data, information, and the experience of information
as human knowledge. Simple data
encoding innovations support anticipatory technology. A clear parallel between the cognitive neuroscience and the
mechanisms that produce situational Orb structures allow the users to
appreciate but the knowledge of neuroscience and the mechanisms that assist in
everyday work. These data encoding
innovations are fully explained and illustrative software is available to the
reader [66].
History
will record the struggle between the two schools, and the eventual revolution
in information science. The changes
that will accompany this revolution will be profound. For example the importance of computer science will be diminished
in order to make way for a science of knowledge systems. Certainly most, but
not all, of the computer science PhDs will oppose this revolution.
The
introduction of natural science to the design of anticipatory architecture
leads one to bypass what are now perceived as intractable problems with the use
of computers. Cyber security and the
control over information by advertising activities is part of the class of
problems that anticipatory technology is able to bypass. Everyone knows the power that the
advertising industry has. Knowledge
science will ultimately reduce this power, as individual people become more knowledgeable
about what they as individuals want to make expenditures on. Advertising is “billed” as fulfilling this
need to know but it does this by pushing information that is often not correct,
or is deceiving in nature. The
knowledge technologies simply allow individuals more control over what is
available to the individual as knowledge.
The
reader should be skeptical, but open to an exposition of results from the
natural sciences and a demonstration of a technology that should be on the
market place by the time this book is published. The exposition provides a foundation to understanding what
natural science has come to know about things like mental event formation and
the nature of natural language. At the
same time, the technology itself exposes multiple bypasses to difficulties we
as a society have with current information science.
Interest
in complexity and in knowledge representation has grown over the past two
decades. Because of this interest, increasing activity exists in academic
scholarship and in commercial and industrial practices, such as eBusiness,
Business Process Re-engineering and collaborative workspaces. There are now many related published
articles and books in this general area.
They include elements of marketing, cognitive science, computational
sciences, operations research, and neuropsychology.
The
principles that support anticipatory architecture are scattered about in the
literature, like the pieces of a puzzle.
When we started working on “Knowledge
Foundations”, in 1995, we felt that the pieces of this puzzle might be put
together. We had some sense of the
difficulties that are implicit in the interdisciplinary nature of our
project. The ten years, 1995 – 2005,
have brought to us a deepening experience of the science and the frustrations
caused by cultural barriers.
The
cultural barriers are merely the tip of the ice berg. The deeper core cause of dysfunction in modern IT systems is
found in set theory and logic. We must
acknowledge that the formal constructions used in computer science are derived
from the foundations of classical set theory.
The second school makes the claim that these constructions do not admit
the natural complexity found in natural systems. The claim is simple, and the argumentation in support of this
claim is extensive. Why can we not
listen to this argumentation and make the adjustments to our information
science?
Program
managers, policy makers and others, make decisions in an environment where the
required argumentation is simply not allowed.
It is the resulting confusion that has shaped the computational sciences
and commercial applications of computer science. The reason why our civic society has not made the adjustments is
that these decision makers recognize the role that natural complexity must play
in the resolution of information sharing problems. This recognition is tacit and leads to behaviors to isolate the
origin of control into the hands of a few.
Our
social confusion is related to the nature of abstraction and the formation of
language, mathematics, theories of science and private theories of self. There is no special field of investigation
that looks at confusions of this type and seeks to resolve problems. The second school shows a path towards a
resolution to this social confusion.
This path leads through a socialization of the power of control and it
is for this reason that we find the knowledge science repressed.
We
feel that in the near future that a science of knowledge systems will take
responsibility for confusions that arose and persisted. In taking this responsibility, the new
science will turn to principles of realism.
What we observe about reality is what we have to explain, even if what
we observe is not logically coherent.
The knowledge sciences must lead to some truth finding, even with this
truth finding is not a comfortable process for those who have acquired
financial/intellectual power.
The
nature of observation and the relationship that observations have to notational
constructions is where the line of attack must begin. An extension of formal mathematics is required.
The
extension requires that the process of induction be left (partially) open so
that individual users might determine the meaning of elements of a symbol
system at the last moment, i.e. in real time.
Human memory and anticipatory mechanism provide this last minute
induction to every living system. In a
computer based anticipatory system, knowledge of structure and possible
meanings can be constructed in advance of critical missions that require a
perception of the facts on the ground.
So we are now able to move the kind of intelligence that individuals
have, always, to a collective system where knowledge of invariance and patterns
of invariance allow a collective aggregation of human information production
into a single system. The result will
be collective intelligence about complex situations typical of social
realities.
Natural
science appears to indicate that many of the mechanisms involved in awareness
are not subject to direct human observation. The experience of information by a
human does not at the same time come with an understanding of the mechanisms
that cause information to be experienced.
These mechanisms are not observable, and yet private experience is
immediate and complete. The metaphor to
logic and computer processing is attractive but incorrect.
This
metaphor must be replaced. It must be
turned on its head. How it is to be
turned on its head is through the notion of stratification.
The
awareness by a human of a situation is always far more powerful than a
dependency on first order predicate logics will capture. What might be more useful is a structural
knowledge of how things in the real world tend to fit together. There is no inference required, just
structural knowledge. The corrections
to computer science are found in sound science that accounts for direct human
observation and for the class of non-observable causes of events.
Stratification
theory suggests causes outside of those that can be observed. Stratification theory honors the best
science when that science looks at the complete picture. How the new science will come to give
language to the notion of stratification is critical to how fast and how far we
will advance in the near term.
The
bottom line is two fold. First, science
has just not gotten to an explanation that is simple enough as yet. Second, our society has fallen into the trap
characterized by the uncritical examination of what is heavily funded by
entrenched institutions. What is funded
is complicated and confused, but is certified as being the best science, in
spite of the fact that the “best science” is defined to be what is best for
those institutions that receive funding.
Shifting the paradigm will allow funding decisions to be based on a
different set of criterion. For
example, individual members of computer science departments will simply shift
their interests towards a more productive activity.
Academic
entrenchment will be replaced by open and clearly defined productivity. Why
should anyone doubt this? Of course
people want to be productive and server a cause greater than oneself.
The
reader is encouraged examine the claim that various mnemonics are used to
reinforce a false notion of science. A
polemic is developed [67],
as polemics often are, so that terms in social discourse are given a false
meaning. The false meaning is then used
to re-enforce the notion that natural intelligence is not a subject for
scientific inquiry. Many people would
say that religion should be consulted here and not science. These individuals would limit the inquiry
that natural scientists would like to make regarding the nature of life. If science itself remains confused by
disciplines like artificial intelligence, then religious and secular
fundamentalists are successful in their inventions. The polemic works when people are confused about what the academy
says about intelligence. The polemic works when religion is subverted by a
narrow viewpoint. The origins of
religion and the origins of science can be seen to be in a balance that is
worthy of the human condition.
Beyond
the current political and philosophical tensions, we see a positive economic,
cultural and social revolution. Not
only anticipatory technology but also other forms of knowledge technologies
will soon rapidly transition markets.
How soon? No one can tell. At one point, however, the economic,
political and ideological inhibition aligned against the formation of knowledge
science will collapse. Economic reality
will cause this inhibition to collapse.
Just
look around. Many social and religious
beliefs show concern about a science of knowledge systems. The polemics express this concern and stand
in the way of an economic benefit. On
the other hand, the knowledge sciences can be applied to the solution of
specific social problems, such as those foundational to a modern medicine. Social interests can be stimulated as
knowledge technologies are applied to entertainment and education.
Knowledge
science has applications that enhance the creative expression of
individuals. Within the Internet
communities, new types of software systems are supporting the management of
collective intelligence in communities connected by web technologies. These communities have shared interests
brought together via connectivity in the web.
With the technologies described in this text, one can develop a process
that accurately measures social discourse in real time and differentially tunes
the measurement to specific communities.
The second school suggests the possibilities
of a structured machine based knowledge ontology having no “required” logical
inferences and no proprietary art form.
The abstract constructions of structural ontology have a capacity to
participate together with a human, in manipulation of structure and
meaning. We believe that anticipatory
software will be used to "mediate" human discussions, and thus has
the potential to bring web-based discussions to a higher plane.
Anticipatory
technology depends on human cognition to make subtle corrections to the
processes of algorithms. In exchange
for this human touch, the technology opens up the human induction process. Individuals and communities develop symbol
systems that can become empowered with knowledge processing systems, like the
Adi structured abstraction ontology [68],
the Stephenson structured abstraction ontology [69]
for cyber attack mechanisms, or the Ballard knowledge processor [70].
In
anticipatory technology, an action-perception event loop is defined that
records certain parts of decisions made by the human in a fashion that builds
two types of artifact repositories, one related to memory of the invariant
aspects of the past experiences and other related to the environmental
conditions. Over time, this artifact
library assumes the role of preserving a memory of text read, messages
exchanged and decisions made. The
artifact library is organized into a structural ontology using the generative
methodology that we are working to establish preliminary knowledge about.
The second school establishes the historical,
scientific and notational foundation preliminary to the exposure of a
generative methodology and its application to specific objects of
investigation. The second school focuses on
philosophical viewpoints, notational devices from logics, semiotics and
physics, and a review of the natural sciences as expressed in cognitive
neuroscience literatures [71]. Core to this focus is an understanding of
the nature of an induction by a human mind producing an abstract representation
of some aspect of experience. Induction
is core to the phenomena surrounding the experience by humans of language,
mathematics and the formal constructs of science.
The
machine processes cannot know and cannot understand the meanings or the context
of these artifacts. Much like the book,
the computer is a place to put an abstract representation of human
knowledge. The machine can be used to
develop models of anticipated meaning based on the composition of the
invariance produced from measurement. A
validated theory of type becomes available as part of the computational
process. The artifacts are sharable
when the process is revealed in an accessable curriculum. The creation of a simple technology is now
seen to be a function of the average user’s educational experiences.
In
the new information science, an individual human manages the abstraction
process producing computer-based categorization of a theory of type. The technology does not overly encumber the
individual’s own tacit knowledge of situations. The resulting new capability has radically different properties
for any of the current generation information technologies. This capability is consistent with any
individual’s interest in creative expression.
It
is understood that not everyone is interested in creativity. However, the inability of institutions to
deal with change is often a function of the degree to which human creativity is
discouraged.
Section
4: Use philosophy
In
developing the knowledge sciences curriculum, some sorting of “facts” has to be
made, since not all of the scholarly literature is equal. Some deep mistakes can be seen, with
hindsight. Some voids are present that
need to be filled in.
The
most critical void is in mathematics curriculums and misplaced (under)
expectations made on average students.
The expectation is measured against algebra and the calculus. This measurement of student ability and
interest is unwise. Not only does it
fail to measure student ability, but it forces most students to turn away from
mathematics and science.
The
proposed “science of knowledge systems” curriculum modifies the standard
university curriculums to include more material from the history, foundations
and philosophy of mathematics. This new
material would justify the importance of abstraction and place the formation of
abstraction in a context that allows the students to understand that
mathematics is but a mere language.
This curriculum would teach evolutionary theory along with the theory of
intelligent design. Both would be
taught as theories of science supported by objective evidences.
Most
freshman students have developed an understanding that higher mathematics is
meaningless to them. Due to experiences
in school they have learned that they cannot learn “mathematics”. Central to a
new curriculum will be instructional materials that help young students
understand the nature of abstraction.
This means that freshman college students will re-learn the foundations
of arithmetic and will address intellectually challenging and interesting information
about the induction of the set of integers.
The induction of the integers arises first from the need to have
accounting for purposes of commerce.
The
success of counting numbers set up the grounding of science in a numerical
model of reality. It is here, in spite
of the many successes of modern engineering science, that one may ask questions
about alternative “inductions”. The
theory of ontology formation is foundational to a natural science of
complexity. The recommended curriculum
first develops the concepts of arithmetic and then extends, not to algebra, but
to upper ontology such as the ABC ontology [72]
The
induction of abstraction for the purpose of making sense of the world does not
have to involve the numerical model [73]. The induction of geometry is very closely
related to the induction of the integers (see the work on inductive informatics
by Lev Goldfarb [74]). The application of ontology to medical
science and to the social and psychological sciences is what we have not as yet
seen. We first have some work to do
with curriculums.
In
a renewed mathematics and computer science curriculum, elementary mathematics
does not become inaccessible due to a specific set of confusions about the
nature of abstraction. The nature of
abstraction, in the context of an induction of the set of integers is placed in
a social and cultural context. Other
forms of symbolic representation of experience can be demonstrated. In fact, we are able to made presentations
about the induction of knowledge processors.
John Sowa, Richard Ballard and Tom Adi have each developed specific
knowledge processors, which have been available as software systems since the
early 1990s.
In
our schools, the educational system must not elevate engineering above the
natural sciences. High school training
in basic mathematics must lead the student into natural science; not the
engineering sciences, but the natural sciences. Those students who wish to devote time to engineering must be
shown that cognitive and social problems are not merely a question of good
engineering design. A central element
of the proposed curriculum addresses the relevance of the topological notion of
nearness to mainstream text understanding technologies based on theme
vectorization of word occurrences in text [75]. Is it reasonable to ask about the nearness
of the concept of love to the concept of hate, for example? The arithmetic concept of nearness is exact
and precise. But this notion that
concepts can be “near” to one another is imposed on semantic technology without
a full consideration. There are
alternatives, but these are not explainable within the information technology
paradigm that our society allowed to develop in the second half of the 20th
century.
A
theory of cognition is available in the neural network and genetic algorithm
literatures. This work represents a
good start. But the literature leaves
many basic questions open and unresolved and continues to be overly
mechanistic. This literature is to be
supplemented by scholarship that goes to the basic questions about how human
memory, awareness and anticipation functions as an expression of natural
mechanics.
The
objective is a practical one. How does
a student use HIP tools? Can the
student be informed by a deepened understanding of the relevant natural
sciences? Given the current
curriculums, how can our children learn a new type of information science; one
that is appropriate to the age in which he or she will live? How are hard problems in social and
cognitive science to be framed?
For
example, human discourse relies critically on the use of a "time
lens" to gather from real-time experience two classes of "subtleties
of meaning" [76]. Anticipatory technology exploits a time lens
based neuro-cognitive process architecture, as discussed in Chapter Four of the
Foundations. The first application of anticipatory
technology was made in 2002 in response to intelligence community needs. A high level decision was made, a decision
that originated in a request from the President, to create a technology that
maps the social discourse in Muslim countries, and to use logics over the
constructions in this map to anticipate Muslim community responses to
Presidential actions and speeches, see Chapter Nine in Foundations.

a b
Figure 3: One of the research tools for Ontology referential bases (Orbs) and
the corresponding ontology lens
Prueitt
(2002) invented an ontology lens and the fields of differential ontology and
formative ontology as part of his work on this system. This technique allows the focus of special
graph constructions; called Ontology referential bases (Orbs), that are formed
as a representation of the co-occurrence of invariance in measured sets, of
text with natural language expressions.
There
is very little political insight into how the lens works in social
discourse. So, for example, the social
discourse after the 2004 elections often involved polls whose absence of
insight was profound. Long periods of television
time are used to explain away the sense of mismatch between what pollsters have
to say and what people feel and talk about.
We saw these explanations as a reinforcement of the polemic that creates
the impression that the television experts truly understand the opinions of the
American people.
The
issue that we are raising in the preface to the Foundations is that the notions necessary to
understanding the nature of social discourse is absent in the media
representation of the social discourse. The technology that we have developed provides an alternative
means to measure the collective need to understand ourselves. The alternative involves a non-numeric, non
geometric, induction following a computer-based measurement of co-occurrence
patterns in archived text organized in a proper temporal order. The in-correct attribution by some formal
logic about the “nearness” of one concept to another concept is not made. These notions about how things are related
are left to the individual awareness in real time. The development of informed judgments about what the opinions of
the American public are is left un-affected by the mechanisms that support the
polemics. The great diversity of
opinion is allowed to be manifest without ranking opinions as being acceptable
or better than a “mainstream”.
It
is not true, however, that structural ontology supports the development of
social relativism, where there is no truth outside of mere community
consensus. Truth finds a deeper
expression in multi-culturalism and the respect for alternative viewpoints that
are not those now controlled by the polemics.
Structural
ontology has three levels, and is stratified in exactly the way we have
represented to be essential to a knowledge technology. Several examples have been developed and is
now available as software. One such
software system, developed and expressed as commercial software by Adi,
measures variations of letter patterns in text. This measurement avoids grammar and semantics of words. From the measurement, a subsetting occurs
within what is in essence a substructural periodic table.
A
second layer of abstraction was constructed to express a theory of natural kind
related to the types of expression that humans need to make as part of everyday
experience. A part of this second layer
is triggered by letter patterns. These
patterns are measured in a repository of text using simple algorithms. The trigger focuses, or subsets, the second
layer constructions, resulting in the production of a representation of the
social discourse occurring in that repository.
This
notion of a time lens is not a question of philosophy but one of empirical
observation and proper use of terminology. The proper terminology suggests that
human experience, and processing, of subtleties of meaning are complementary in
nature and form upper and lower envelops to the coherent packet that is
produced by a "Fourier like transform" of energy distributions
(Pribram, 1991). In our view, the coherent quantum-electric-chemical packet is
formed from the emergence of autonomous systems from a substructure, knowable
as statistical objects, and an ultrastructure, known as context. Quantum, electromagnetic and chemical
processes are involved.
Emergence
is into a middle layer that appears as a complete world to the “thing” that is
created. This may be true because the
process of emergence itself establishes the broad relationships and potential
for relationship as part of the formation process. The physical power of phase coherence is seen in Pribram’s
neurowave equations as a control constraint on the emergence of mental
expressions. We speculate here, of
course. But the idea is that one can
theorize about the nature of coherence in a different way using stratified
theory than one can using the classical theories. Observations about coherence and emergence are placed into
experimental and theoretical frameworks and can be tested.
In
our work, a metaphor to the quantum mechanical view of the natural world is
often made, since atomic phenomenon is known as statistical objects and the
chemical compounds that make up this world are constrained by a set of
conservation laws. We conjecture that
these conservation laws are not “universal” except within an organizational
level. For example, science simply does
not know what the conservation laws are for string phenomenon. This radical conjecture about universal law
is not something that can be proved, as yet, but the alternative cannot be
demonstrated either. As the reader will
see in the Foundations, the conjecture has several corollaries
that apply to a theory of mental event formation.
The
second school suggests that all things that interact within a set of
conservation laws are technically part of the same level of organization. The “knowledge processor” is a computer
encoding of three layers of abstraction.
These three layers of abstraction corresponds to three levels of
organization that cognitive neuroscience tell us .are actually involved in the
functioning of the human brain. The
substructural and ultrastructural levels are organizational abstractions that
we develop as a means to produce the specific constructions within a mew class
of knowledge processors. Notions of
completeness and coherence are to be applied within, but not across, the layers
of organization. The knowledge
processor works by allowing a measurement process to connect with real event
structures. Measurement grounds the
knowledge processor into a pragmatic context only accessable, we suggest, in
the moment. However, the notion of
coherence and completeness can be applied to abstract knowledge
representations, as we know from foundations of mathematics literatures.
In
the case of social discourse the event structure is measured, by algorithmic
parsing at a substructural layer, the language being used. The middle layer of a structured ontology is
also complete in a technical and observational sense. Using HIP we place ourselves into this middle level. We produce a measurement of the event
structure in real time. We can see
event structure that is common to our thoughts and the pictorial or graphical
representation of measured invariances.
The magic occurs in the human mind, not in the mythological computer
experience of reality.
The
technology that arises from human-centric information production within the
tri-level architecture is complete observationally, since what can be observed
directly is part of a single reality.
But we do experience the paradoxes familiar in the Lewis Carroll’s Alice
in Wonderland. In classical theory,
those sets of causes that cannot be observed directly, like the contents of
someone else’s introspection, are treated as not part of the “complete
world”. The social difficulties that
arise, because of this treatment of the other person, is then “seen” as
irrational.
The
problems with coherence do not go away, and in a stratified theory
terminological reconciliation must be accounted for in the “cross
organizational scale” transformations.
We have many tools that address this issue. In Chapters 6 and 7 of the Foundations
we look at Q-SAR (qualitative structure activity relationship) analysis and the
Soviet era logics called quasi-axiomatic theory. The appendix reveals a simplication of the Soviet approach to creating
abstraction related to the mechanics of cross scale processes. We also see reconciliation process support
in the knowledge processors revealed within three or four commercial software
systems.
The
tri-level notions make sense to some but not to others. There is a question of perception and in
seeing evidence in a specific light.
For example, in the stratified theory, the two classes of non-observable
artifacts, related to memory and anticipation, each have what the other class
does not have. Statistical artifacts are independent of another. One has one or one does not. But the conservation laws come “together”
all at once, so to speak and entangle the output of memory mechanisms with the
mechanisms of anticipation. We
experience a single awareness of the world.
This
difference in non-observable classes is due, in part, to the difference in time
scale. The atomic elements, of the
memory mechanism, are categories of occurrences, what we will call
categoricalAbstractions or cA.
Stability over the set of cA atoms is due to the forcing of a
categorical folding that places slightly different elements into crisp
categories. The category replaces the
identity of the individual elements, in an context where the system uses
elements from a category as non-differentiated. This is much like factory workers in a factory. The roles required by the factory dominate
individual differences.
One
might observe that the boundary of a category is sharpened when categories
develop strong relationships with other categories as part of the processes
involved in the formation of compounds.
Why would a category become more crisply defined in those cases where
other categories are developing that have many relationships to the first
category? The reasoning as to why seems
to me to be self-evident. However, I
understand that this self-evidence is due to my training and knowledge of
literatures. Likewise, the environment,
in which composition of atomic element aggregate together, has self-organizing
properties. Compounds only form if
there is a need by the environment that they form, and so only a small number
of possible compounds actually do form.
Is this self-evident to the reader?
Other
fundamentals, like the notion of coherence, are changed in appearance from one
level of organization to another. Because we “live” in the middle world,
coherence is seen as a property of middle world inter-relationships. In the substructure; however, the meaning of
relationship has a different tone than does the meaning of relationship in the
middle level.
Perceptual
memory is of categories of invariance that repeat across multiple
instances. So we encode colors and
textures and re-combine these encoded invariants later into some coherence
packet that we experience as memory. A
color or texture may be inherently harmonic, as perceived aesthetically; but
logical coherence between a specific color and a specific texture is a matter
of an interpretation that has been contextualized. Meaning is established, we conjecture, via the particulars of the
cross scale phenomenon. Meaning
emerges. When an event develops, the
meaning of the event comes with the formation process. After the event has occurred, one can have a
remembrance of the meaning, but that remembrance is an abstraction. Again, is this self-evident to the reader?
We
have pointed out that the neuropsychological literature provides strong
evidence that subtleties of meaning are encoded in biological and environmental
medium. We can represent what is
encoded as statistical or categorical artifacts. The use of artifact formalism
is useful in revealing nuances and in developing a representation of what can
be experienced as knowledge by the human.
The structural ontologies are developed from the informed induction of
substructural and ultrastructural invariants.
So
in summary; the tri-level architecture exploits a separation in the physical
process supporting natural intelligence by creating two classes of abstract
artifacts. The lower class of artifacts
is about the substructural invariance in the world and the upper class is about
the non-stationary of the situations in which substructural invariance is
manifest in observables. Natural
intelligence makes this separation, not for arbitrary reasons but because natural
intelligence, unlike artificial intelligence, must depend on actual physical
reality for substance.
So
how can this difference be used in the context of computer based anticipatory
technology? We have suggested that
special knowledge artifacts can be generated and composed into sign
systems. Then the logical atoms of
these systems are developed statistically and assembled into dynamic
categorical policies to represent the discussions of a community.
Because
context is lost in a formalization process, anticipatory technology needs to be
based on a theory of interpretive control and a notational system that provides
a means to express this control. We
suggest that this theory and notation are available to us now.
The
natural science that we cite will deconstruct some of the polemics of Western
philosophy, in particular logical positivism and scientific reductionism. The natural science forces upon the
mathematician a challenge to extend the notion of induction to symbol systems
that are not solely based on the ancient notion of a number or geometric
axiom. As these challenges are
recognized, we reveal a new information science, and a maturing of the natural
sciences.
The rest of the draft of this book is at: