Design
Document for Automated Suggestive Reasoning
September 10, 2000
Revised April 27, 2003
Internal Ontology Stream Inc Document
All Rights Reserved
Contents
1.1: Graph theory and a “Unifying Logical
Vision”
1.2: Suggestion Reasoning Object (SRO)
2.1: The methodology of descriptive
enumeration, use cases
2.2: A methodology for constructing
structures
3.1: Extending the ability to communicate
3.2: Automated suggestive reasoning as a
many-to-one projection
Design
Document for Automated Suggestive Reasoning
September 10, 2000
Revised April 27, 2003
All Rights Reserved
The purpose of this document is to bring into
one place our thoughts about innovation and computer software developed to
bring specific innovations into a market.
We then extend some fundamental principles to show a consistency between
routing and retrieval technology and our current intuitions.
The First Knowledge Sharing Core [1] is a
project that is bringing several patented innovations together to demonstrate
Information Production [2]
capability.
Section
1: Market definition
In the last century, foundational work on
information technology was extensive, and yet critically fragmented by
unsettled philosophical issues. The
fragmentation was not properly managed largely due to the world’s scholarly
community not having a standard formal understanding of what information is. Similar confusion exists in the scholarly
community over what human knowledge is.
Some scholars now express the view that, because
of these confusions, the world’s ecological-business system has yet to make a
full transition from a primarily industrial age to a pure knowledge age. This historical perspective brings light on
how the emergence of knowledge technology markets is being inhibited.
It is clear that deeply rooted information
control will continue to have a deep effect on economics and society. During the closing decades of the twentieth
century, computer science has dominated discussions with business process
re-engineering, expert systems, and knowledge management.
Promises have been marginally meet, and more is
expected than delivered. For many, this
observed impedance mismatch, between promised and expected, leads to the
question:
“What is the
relationship between the deeply rooted control of information and the
mal-performance of first generation information technology?”
BCNGroup founders [3] have developed an historical view over
this question. The first generation
information technology was built based on analogies to specific scientific
paradigms. These paradigms enforce a
viewpoint that requires complexity to be modeled in a purely reductionist
fashion. Reduce to rules. Reduce to processes. Reduce to knowledge. In spite of the low hanging fruit, this
foundational work is incorrect in the limit.
Taken as a limiting strategy the reduction of all things to a computer
program forms the basis for the artificial intelligence mythology [4].
Information Technology exists because of the
commercial success of Information Technology companies. The problems of the client are important to
the degree sufficient to meet market expectations, but expectations were
low.
We claim that the primary reason for the
development of the culture of Information Technology is the absence of a
standard understanding about information and about human knowledge.
Several technologies are positioned to achieve
the significant breakthrough we anticipate [1]. Some examples of how these technologies
integrate together are derived from representational theory and from new data
encoding patents. These technologies
are consistent with each other, and in line with other patents that provide
protection for our innovations.
For automated suggestive reasoning, the breakthrough
technology is the tri-level architecture [5]. Data encoding and representational theory is
core to this technology [6]. The architecture requires that events (the
middle level) be separated from context (the upper level) and dis-aggregated
into a memory core (a substructural level). The trilevel is used in the context
of a navigational aid within the computer addressable world [7] of locally defined informational
fragments and structures.
The First Knowledge Sharing Core is to be the
first example of the integration of these innovations in support of Information
Production [1].
1.1: Graph theory and a
“Unifying Logical Vision”
The phrase “Ontology Stream” is used as a noun
to indicate a virtual communication space where taxonomies and concept maps are
moved about within an XML peer-to-peer environment. We are developing a new technology called Information Production
via ontology streaming.
We can regard a node as a location within the
taxonomy, or more generally a location within the structures of the ontology
(such as an generalized conceptual construct structure). The ontology appears to “stream” as the
user/program moves from one location to the next. The experience may have textual, symbolic or auditory form.
A user/program experiences representations of
knowledge during this motion. Underlying formalisms can express a calculus of
over encoded data structures as a system of metrics on knowledge
representational changes.
The formal tokens of a traversal path are a
measure of the history of the use of structures within the ontology. At any one
location, the user/program’s actual path within the ontology is a simple
connected graph, actually the concatenation of a number of line segments. However, the location itself has various
routes from that node to other locations in the ontology (see Figure 1b). The tokens of the path are indications of
the thought processes engaged by the user/program.
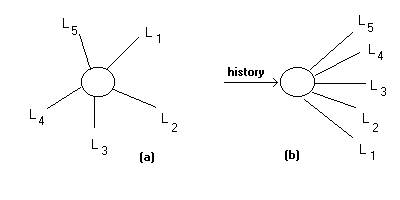
Figures 1a and 1b: A
Peircean graph (a) is used to enumerate the possible future paths (b) of a
traversal of the structures of ontology
The CCM construct [6] is a
structure that frames the tokens of machine-readable ontology in a specific
fashion. This special structure has a
correspondence to the way human natural language is written. In the CCM generalized conceptual construct,
parts of speech are loosely organized into sections and subsections, and into
paragraphs and topics. The
correspondence between the structures of the generalized conceptual construct
and written language facilitates the projection of an automatically generated
report; written as natural language, or in some database format, or as a XML
stream.
Automated Suggestive Reasoning can be projected
because much of the structure of real time cognitive reasoning is represented
in computer addressable form.
Automated Suggestive Reasoning within a
structured taxonomy depends on having:
1) a usable representation
of a history of taxonomy traversals, and
2) special nodes in the
taxonomy where some judgment is anticipated.
The representational issue can be solved in
simple or more complex fashion.
Randomly assigned, semantically pure, tokens can be used for representation,
and still give the user the feeling that the software knows the needs of the
user/program.
Taxonomy traversal is one way to establish
context. The history gives the location
a temporary context. Different
histories can lead to the same location.
The location plus the context is changed, from one event to the
next. The location itself can be said
to “afford” moving from the location to one of a set of other locations. This affordance is represented well as a
Peircean existential graph (see Figure 1a).
The tri-level architecture is an extension of
the logics of C. S. Peirce (1839 – 1917).
This extension adds the notion of environmental, or contextual,
information. The logic of Peirce is
bi-level, substructural and compounds, and reflects his 19th century
training in chemistry. What has been
missing from his work and from work on computational emergence, are the notions
of social-affective information [8] that constrains
the aggregation of atoms into compounds. This constraint is mapped as bases of
attraction [2]
Simple traversal of the nodes of an ontology
using the tri-level architecture has been prototyped. The prototypes, done in 1997 and 1998, show an interesting
personalization of a path an individual takes while visiting a series of nodes
in a structured taxonomy. The
personalization is an aggregation of context, only partially captured by the
aggregation of representational tokens during the traversal. The human keeps
some of the personalization as awareness of situation.
We will not report the full results now, since
some work needs to be done to reproduce previously discovered traversal
characteristics and to discuss the science of interaction between an evolving
image of self and an evolving knowledge representation of context.
The bottom line is that a user gets the feeling
that the software knows the needs of the user/program. The 1997-1998 prototypes told us (Prueitt,
Murray and Kugler) that this bottom line could be achieved easily using the
trilevel architecture and very simple token representational algorithms. Specifically the members of the community of
knowledge scientists are inventing various means to representation that we feel
are “semantically pure” and simple to implement. The First Knowledge Sharing
Core [1] is
demonstrating some of these innovations.
The selection of the next location to visit is
made using the simple voting procedure described in Prueitt’s published work.
This selection process requires that each of the possible next locations have a
representation that is aggregated from a core memory set. This core memory is the atomic invariances
that are used across the entire enterprise to represent locations, histories
and categories. The core memory, like
human memory, is developed so that it has the property that any experience or
system state can be operationally represented by some composition, or
aggregation, of some subset of the set of all core memory elements. Data-morphic transformations of these
compositions are possible and quite simple.
The core memory elements can be thought of as
atomic, in a direct analogy to the atomic elements of the periodic table of
atoms. Some 90 years ago, C. S. Peirce
called this analogy the “unifying logical vision” or ULV. The ULV was then extended, specifically by a
segment of the Russian cybernetics community, and made richer with Mill’s logic
and situational semiotics. Other
citations of scholarship indicate that the ULV is a core understanding that is
really required to build knowledge technologies. The ULV is the minimal complexity that is required to establish
the scientific grounding for the trilevel architecture.
1.2:
Suggestive Reasoning Object (SRO)
Our strategy is to implement the
minimal infrastructure necessary to demonstrate the feasibility of operational
and flexible automated suggestive reasoning in the context of generalized
conceptual construct based inductions.
The generalized conceptual construct’s internal data structure has what
we describe as a general class of “affordance indicators”. A question is one subclass of affordance
indication, since the question affords an answer or answers. These questions
may be given a-priori resources required to activate automatic suggestive
reasoning.
If simple resources are available
to a question container, it is possible to call the Suggestive Reasoning Object
(SRO) and receive a plausibility measure for each of the possible answers. The
interface for showing this measure will be discussed now. If a human is navigating conceptual
constructs (existing as machine readable ontology such as Topic Maps) then a
comparison to actually chosen affordance indicators (such as answers) are
encoded as structural transforms that build and preserve history dependencies
using evolving
transformation systems [10].
Here are six types of functions
or data structures that we need.
1)
Initialization
a.
Establish a category spectrum
(policy) for each selected question
b.
Set representational control
options
1. Represent in semantic
free form
2. Represent with
linguistic technology (Oracle ConText, Semio, VisualText)
3. Represent with
Bayesian/Shannon algorithms (Autonomy)
4. Represent with stratified vetting
(Tacit Knowledge Systems, SchemaLogic Inc.)
2)
Memory Core
a. Set representational
algorithms (initially semantic free)
b. Develop fundamental set
of tokens
3) Recall
a. Make representation for
any history, event or category
b. Validate
representational structure (SchemaLogic Inc, Topic Maps)
4) Spectrum
a. Called by the container
object only in specific cases
b. Stores the category
representations for selected questions
5) Histories
a. XML file description of
histories
b. Show histories using
graphs
6) Management
a. Add/delete or modify
questions nodes to the set of nodes equipped with automated suggestive
reasoning
b. Make manual changes to
representations of events, locations or histories.
Semantic connectivity within a
set of tokens is an issue of great importance.
Our memory core is a simple numerical spectrum, having no intrinsic
relationship between tokens. A deep methodology
for constructing “semantic free” spectrums is discussed in our patent
preparations. The alternative
representational methodology is standard word phrase (or n-gram) tokenization
of events. The Continuous Connection Model (CCM) concept definition is grounded
in the 1994 and 1997 ATS patents [6].
In word phrase tokenization, the
inherited meaning for words is subject to interpretation errors and shifts in context.
Humans give inherited meaning when we think and converse. The unsolved problem with automated
linguistic tokenization is that proper generation of tokens is subject to
subtle errors (Oracle ConText and Semio).
By converting tokens into semantic free symbols, we avoid characteristic
mistakes made by systems like Autonomy, Tacit Knowledge Systems, and Semio Inc.
The tri-level algorithms then create a formative
ontology that is constrained by semantic valances and human inspection. The simplest of these algorithms is the
minimal voting procedure [11]. The
more sophisticated algorithms are SLIP [12] and quasi-axiomatic
theory [13].
Section
2: Descriptive enumeration
This section focuses specifically on the
evolution of an objective methodology for developing generalized conceptual construct
structures. We envision this
methodology as the basis for certification programs and for consulting income
to the community of knowledge scientists.
Our Consulting Methodology has three components:
1) A methodology for
constructing generalized conceptual construct structures
2) A methodology designed
to open doors within properly identified markets, and to negotiate the initial
conditions for business enterprise implementation.
3) A Certification program
Currently we have work on the Methodology for
Implementation of Consulting Methodology. In addition to certification for the
Methodology for Implementation of Consulting Methodology, we have work on a
curriculum for training Information Technology professionals in all aspects of
product design, metrics and maintenance.
However, these components are not directly
addressed in this Design Document. We find it important now only to indicate
the relevance of these other two components when we frame the scope of
automated suggestive reasoning.
The central concept of the methodology is the
enumeration of topics. The enumeration
is fitted into a generalized conceptual construct topic hierarchy. In Section
2.1, we have some use cases that suggest how enumeration proceeds. In Section 2.2 we have a description of
issues that frame the development of a generalized conceptual construct within
the business environment.
Section 2.1 and 2.2 bring into the Design
Document the background necessary to understand how our innovation is viewed.
This background sets the stage for seeing automated suggestive reasoning in the
context of a technology extension for human communication.
2.1: The
methodology of descriptive enumeration, use cases
This section is modified from a June 27th,
2000 document, “Modeling within the Enterprise”. User/program and program must work together.
C-1:
Create generalized conceptual construct framework and containers (the dialog
tree)
C-1.1: Work top down to
create the generalized conceptual construct framework and containers
C-1.1.1: A user/program works top-down, completing all top sections
first and then all parts of the next level of organization.
C-1.1.2: At each level the user/program attempts to fulfill informal
completeness and independence conditions.
C-1.1.3: Finally the user/program develops topics under each of the
lowest level of the tree structure.
C-1.2: Work bottom up
to create the generalized conceptual construct framework and containers
C-1.2.1: The user/program develops a set of questions such as a questionnaire
or instructional type test.
C-1.2.2: For each question,
user/program develops topics and auxiliary information that is related to the
question.
C-1.2.3: A clustering algorithm
routs topics into bins (categories) and these bins identified with a concept
C-1.2.4: Category bins are allowed to dynamically evolve as new
topics/questions are introduced.
C-1.2.5: A clustering algorithm
clusters bin representation into higher levels of organization.
C-1.3: Mix working
bottom up and top down to create the generalized conceptual construct framework
and containers
C-1.3.1: The use develops the structure by working either top-down
(C-1.1) or bottom up (C-1.2)
C-1.3.2: Two partial
generalized conceptual construct frameworks with containers might be merged into
one.
C-1.4: During this
process (C-1.3) the user/program will specify some or all of the properties of
each of the containers as the tree is extended and populated.
C-1.5: after all of
the topics are developed, user/program attaches questions to each topic.
C-1.6: in some cases,
user/program re-contextualizes specific topics or question containers and these
containers are made accessible from different locations in the ending tree
structure.
2.2:
A methodology for constructing generalized conceptual construct structures
The following issues characterize the
development of a generalized conceptual construct:
1) A survey and interview methodology produces an enumeration
of information flow events within an enterprise.
a. It is noted that an event
is not simply something that occurs, but something that occurs on a regular
basis
b. Regularly occurring
events are found via frequency analysis and co-occurrence metrics. This
principle is central to classical data-mining methods
c. Humans identify regularly
occurring events. The knowledge of
these events can be communicated using natural language or (now) a generalized
conceptual construct structure.
2) An information flow model is developed to include
both computer information exchanges as well as information exchanged during
human conversation.
a. The information model is
acquired through professional systems analysis
b. This analysis provides a
stand-alone value similar to Business Process Re-engineering consulting
services
c. The ability to conduct
survey and interviews and to do the systems analysis is an ability that we
enhance and then certify.
3) Systems analysis leads
to the identification of events where a generalized
conceptual construct provides
structured communication of knowledge between
stakeholders.
a. Structured generalized
conceptual construct communication brings reminders to stakeholders as to what
knowledge is useful in making judgments
b. The regular vetting of
judgments via a generalized conceptual construct knowledge structure provides
accountability when measured against outcome metrics
c. The generalized
conceptual construct reduces the time required to make a full reporting of
analysis and judgments
Section 3: An extension of natural language
Classes
of technologies exist that support the advanced management of knowledge
representation. Our intuition
anticipates integrating these technologies into a single enterprise system with
products as a core feature.
3.1: Extending the ability to communicate
We
take the position that the generalized conceptual construct internal structure
provides an extending technology to human communication. This is a simple claim.
Communication
that uses generalized conceptual construct structures is different from
conversation with spoken language in that generalized conceptual construct
communication can be one-to-many or many-to-one. One-to-many is accomplished sometimes, but many-to-one requires
some new capability. In our viewpoint,
many-to-one communication will be accomplished through concept aggregation and
automated vetting of community viewpoints.
In the following sections on suggestive reasoning we begin to unfold how
this is accomplished using semantically pure knowledge representation, the
trilevel architecture, and the voting procedure.
The
trilevel architecture is capable of pushing and pulling information about
“people, places and things” and to do so in a way that is computationally
simpler and, in theory, functionally superior to the push and pull technology
used by Tacit Knowledge Systems, Autonomy and Semio. The year 2000 value of this market space exceeds 6 Billon
dollars.
Our
current product does not, however, compete in the Autonomy market space. We are looking forward into a new space that
is characterized by knowledge discovery, knowledge use, and knowledge
sharing. This new space is just
becoming defined. We have the unique opportunity to establish an early
presence. Our current intellectual work
and patent policies are directed at establishing this presence.
Interpretation
and generation of human knowledge is facilitated by an automation of how humans
create the generalized conceptual construct structure and how questions are
answered. This creative process forces
human thought to conform within a form (the generalized conceptual construct
internal structure) that can then be algorithmically transformed. The structure, like human language, is not
knowledge unless perceived in the mind of an individual.
A difference between human conversation and
generalized conceptual construct knowledge sharing is due to “form-based”
computational processes. We theorize
these processes will be accomplished using data-morphosis.
The “technology” for data-morphosis is an
expression of our research and the work of certain scholars. Within the
formalization of the theory, data is seen to transform into knowledge
experience within a second order semantic control system. The scholarship (of Pribram, Bohm, Maturana,
Varela, etc) supports this notion.
3.2:
Automated suggestive reasoning as a many to one projection
Automated reasoning is now seen as an
aggregation of the representation of past events. The notion of time is not so important here. Thus we can aggregate over responses that
arrive from many people. Many-to-one
structural coupling flow from principles developed within the ontologyStream technology. Knowledge is projected from many-to-one, and
from the past-to-the-present.