ORB Visualization
(soon)
Friday, June 11, 2004
Third Tutorial
on OrbSuite™
The June 27th release of OrbSuite™
Project management in the
OrbSuite ™
Relationship to work on Earth
Observation Science data
The use of concept separation theorems to produce
conceptual recall
Project management in the
OrbSuite ™
We take all 312 Aesop fables by identifying a folder having 312 files, each with one fable. This is a small collect of text, consisting only of 200 KB of data.
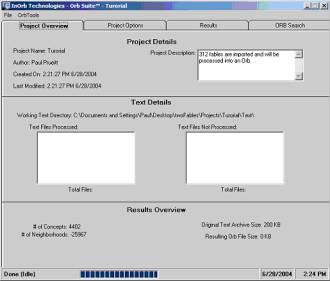
Figure 1: 6/282004 project Overview
Project management in the OrbSuite ™ is still evolving, but already the OrbSuite has many important features. Creating a new project and developing an Orb set is easy. One needs only the text files saved in ASCII text.
The simplest “n-gram analysis” is used in this June 27th release, and is the measurement process most directly discussed in the Orb Notational Paper. This measurement uses a “standard” work level n-gram measurement of the text to produce a set of neighborhood relationships, based strictly on proximity.
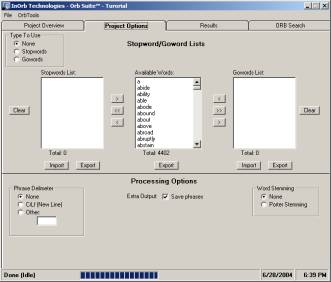
Figure 2: The simplest processes uses all words
In Figure 2, we find that there are 4402 unique words in the 312 fables. The frequency of occurrence is not recorded due to a principle that we establish that suggests the patterns of occurrence are what we are looking for not the frequency of occurrence of single words. We feel that frequency is greatly over used because it is simple to get at. One uses stop words to remove the most frequently occurring words as a balance. These techniques moves one further away from category theory, where one instance is sufficient, to statistics where very large data set are needed to produce “results”.
The methods of categoricalAbstraction, that Prueitt invented 2001-2202, have a fractal data encoding process, using referential information bases (RIBs), and can produce small and accurate information about the co-occurrence patterns from very large, massive, data sources. So the work being discussed here competes with statistical methods over massive data sources, and also works on small datasets. One consequence is that informational patterns can be discovered using small data sets, and then these patterns can be used in the definition of measurement processes over massive data sets.
A phrase, like “anticipatory web”, would be a pattern of occurrence where the words are sequential. The n-gram window in the Notational Paper has 5 words, with the center being given a focus and the off center elements not being distinguished. So the words
“anticipatory nature of a web of information” [1]
would identify the

Figure 3: Part of the screen shot of a project with only the text in [1]
In each case the word “small” refers to the name of a text file having on the words “anticipatory nature of a web of information. The word “a” is thus the center of the five-gram:
( nature of a web of )
The Orb encoding is created by the SLIP browsers, as illustrated in a large number of 2002, 2003 tutorials.
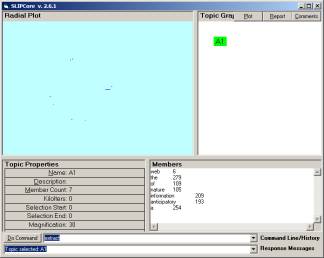
Figure 4: The seven atoms in an Orb encoding
The Orb encoding can be visually inspected using the SLIPCore browser, and the eventChemistry browser.
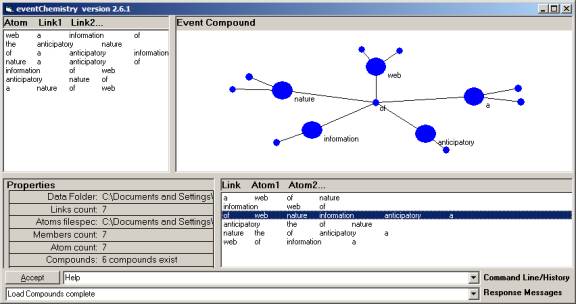
Figure 5: The “of” link in one of the 6 compounds
The figures above should reinforce intuitions about what the Orb technology can do, and to suggest that we are just beginning to reveal what are very natural constructions and processes. In Figure 3 and 5 one sees an encoding of information about the neighbors of the word “of” twice. In longer input text strings, this development of a category of words that are neighbors of a specific word, constructs the topological neighborhood of the categorical abstraction of that word. Because words can be used in different contexts, this process processes an error that has to be corrected at a later point. This issue is addressed incompletely in the section of the National Paper on ambiguation.
In Figure 5 one sees that the concept being referenced by the string of words, [1], is indicated by the two word co-occurrence patterns; “anticipatory web”, “anticipatory nature”, “anticipatory information”, as well as “web nature” and other patterns. Rules can be generated that looks for these patterns, or for any three, or four, word pattern using the words in the neighborhood.
One of the efforts to address this is to use a more complex co-occurrence, such as looking for three, or four, words co-occurring rather than just two. Thesaurus and simple ontologies can also be used to develop equivalence classes and rule sets that depend on knowledge of language. The why to think of this is a full use of some degree of knowledge of language and some degree of knowledge of the world.
Relationship to work
on Earth Observation Science data
Our work on a proposal to NASA would have us use Orb encoding as a means to “mine data” in new ways. These new ways are less confined to the types of relationships that one can define in a relational database. Our group has not been able to extend the simplest form of n-gram analysis so that some degree of knowledge of language and knowledge of the world is in place. But a familiarity with the methods and with the notational paper allows one who is aware of the research literatures, in text and image understanding, to see that this is merely a matter of time and resource.
Perhaps the most important difference between text understanding and image understanding is parcelation or chunking techniques. These techniques produce what might be called the atoms of the universe of observation. Of course organizing the atoms found in these techniques leads to a second level of differences. We will leave this discussion for later.
The use of concept separation theorems to
produce conceptual recall
One has many levels of techniques that create a separation of categorical atoms so that event chemistry formed from bags of atoms has a fidelity to subject matter referenced. In text understanding the state of the art is very crude. The interpretive aspect of language is not handled very well, and requires human in the loop reification of pattern semantics.
In image understanding the state of the art is also quite crude. Feature extraction does not have the individual word as a separable item for analysis. So, for example, n-gram analysis has not “level” to work on. One might be able to produce a level, ie a set of observational atoms, from image measurement processes. Of course this could be promising, but this type of approach has not been developed. If one had such an image decomposition into features, then latent semantic analysis could be done; for example. Perhaps this has been done; but we cannot find evidence of this in the research literature.
What one does not have in the problem of image
understanding that one has in language understanding is the act of
interpretation. Interpretation of the
meaning of words is a refined processes that human societies have developed
based on physics that exists also in other phenomenon. One sees one level of the confused philosophical
problems in constructivist theories of social science, where it is conjectured,
believed, that humans create the physical world by observing it.
In language the word atoms are used in the natural world, as humans communicate, to produce interpretations by living being that have introspection and sets of "logical" entailments that are not accessable to the computer. This is, an aspect of, the fundamental issues being addressed in a on-line discussion between John Sowa and Richard Ballard.
(under development, send comments to portal@ontologystream.com)