Wednesday, August 11, 2004
Tutorial
On the Nature of a
new Memetic Technology
based on
categorical abstraction and event chemistry
edited : Tuesday, August 10, 2004
Two level Fixed Upper Taxonomy from subject
indicators 4
Dr. Paul S. Prueitt
Founder, BCNGroup Inc (1992) and OntologyStream Inc (2000)
Copyright 2004 OntologyStream Inc
703-981-2676
Historical Overview
The development of a novel, simple and powerful technology has occurred over a period of years, and has several key contributors. The principle on which this technology is based has the nature of a specific extension of Hilbert type mathematics and is grounded in cognitive and behavioral sciences in very specific ways.
The technology is a fundamental advancement in science with specific consequences to measuring the human production of information as part of every day social interaction.
Central to this technology is the measurement of invariance across multiple instances. The measurement can be applied to a diverse spectrum of targets. In each application the interface to Orb (Ontology referential base) data encoding, sets of ordered triples, will be slightly different, but the core data encoding and the data transformations are generic.
The final section of this paper develops an illustration where the measurement is not a standard measurement and the semantics, that might be laid over the measured structure, is not obvious.
One thinks about this as stratified category theory. A natural separation of instances from the invariance within instances is used to develop a stratified theory of type [1][1]. For example, if the instance is a sentence, one may look for pairs of words that are co-occurring within that sentence. The measurement of co-occurrence produced a precise relationship having the form < a, r, b > where a and b are co-occurring words and r is the relationship of having co-occurred.
A complete measurement of a text corpus produces a set { < a, r, b > } and this set is equivalent to a graph with the relationships the links and the set of co-occurring words the nodes. The relationship, “co-occurrence of words in text”, is not generic; nor is it the case that the co-occurrence might be conditions on, for example noun or verb types.
We appeal to the notion that regularity in co-occurrence of words within sentence boundaries should be indicators of subject matter. One has to develop empirical evidence that this is so. However, such a measurement is precise with linear dependency on the boundary of our definition of instance, eg as sentence or multiple sentences, so that if the boundary is increased than the number of co-occurrences increase.
The set of words considered significant can be altered as can the identification criterion for words having multiple potential contexts. The definition of relationship can also be varied in a complicated fashion by introducing entity extraction rules or other types of parsing rules. The precision of these measurements allows the empirical science to be developed in an orderly and objective fashion.
Subject matter is modeled, in the abstract, as the basins of attraction within a mathematical topology on a graph (if discretize in some fashion) or within a mathematical topology as a continuum.
Model for the structural holonomy between continuum and discrete formalisms
Differential Ontology Framework (DOF), allows a structural holonomy between discrete and continuum formal models, but does not address the issue of ontology reification.
The co-occurrence relationship produces a discrete measurement of the subject matter being exchanged within the social discourse. Latent Semantic Indexing (LSI) is a well-known technology that uses linear algebra and Hilbert space mathematics to create a continuum model, a Hilbert space manifold, of the subject matter being exchanged in the social discourse. It is argued elsewhere that LSI topology can be mapped to a discrete graph having a type of structural homology to the LSI manifold.
We use the terminology of memetics, with certain distinction being made regarding the ontic status of a meme as a replication mechanism DUE to the expression of individuals within a social system. This means that we find a fundamental distinction between the replicator function of genes and the replication of indexical frame (Lissack 2004).
If, on the other hand, memes
are redefined such that the evolutionary selection process is no longer an aspect
of the ontology of memes but rather of the environmental niche of which the
memes are evidence, then the field may have other avenues of advancement and a
potential relevance to managers. Such a redefinition would entail recognition
of the relationship between a given meme and the context of the social and
ideational environment of which it is an affordance and which it demands be
attended to. Memes in this casting are a label for successful boundary object
indexicals and lose their privileged status as replicators. Instead, the
replicator status is ascribed to the environmental niches and the memes are
their representatives, symbols, or semantic indexicals.
The indexical is an abstract concept that becomes practical by actually looking for the words that are co-occurring around a central term. What is then a central term? The answer is non-precise in that a subject matter might be indicated, successfully, by more than one specific term. This variability is consistent with everyday experience. In standard taxonomy, we have the concept of a “broad term” which subsumes more than one narrow terms, allowing for an organization to terminology. This b-t/n-t concept has been found useful.
The organization of subject matter indicators into broad-term, narrow-term taxonomy can be mapped to a graph where each broad term is the center of a graphical neighborhood, and the narrow terms are all equal distant from the center.
Section 1: The constructions
Two
level Fixed Upper Taxonomy from subject indicators
We have exposed several
problems.
Q1: How can we fix a specific “upper taxonomy” within the constraints of a small number of nodes and two levels, so that the taxonomy covers the universe of discourse for a specific period of time?
Q2: How
can we provide additional layers, called a hidden taxonomy, which interfaces
with intelligent search and metadata extraction technology, while keeping the
upper taxonomy fixed?
Our solution
is to have human enumeration of a two-level broad-term, narrow-term taxonomy
that is to be fixed for a period of, say, nine months. This human enumeration is matched to a
bottom up adaptive elaboration of a hidden taxonomy using machine based rules
and machine learning techniques.
An addition to this two level
taxonomy we wish to provide an adaptive elaboration of the bottom elements of
the two-level taxonomy so that the taxonomy extends into and covers the subject
matter.
First step: Produce a single set of
taxonomy node candidates
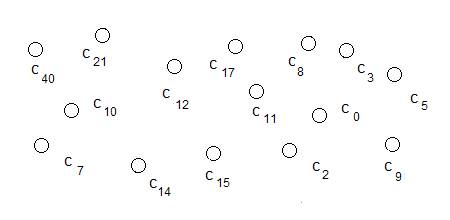
Figure 1:
Taxonomy candidates derived from machine or algorithm
Second
step: Organize the taxonomy candidates into a two
level taxonomy using broad term (bt) / narrow term (nt) relationships.

Figure 2:
Figure 1 organized by BT/NT relationships
Figure 1 and 2 indicate a top
down enumeration of taxonomy using polling instruments and knowledge
engineering/management methods. The
bt/nt relationships are used. For example,
c(21) is a broad term having three terms,
{ c(11), c(3), c(40)
}
with a more narrow meaning or
context.
Once the
upper taxonomy is fixed we have a finer resolution of subject matter indicators
that MUST match the bottom layer of the upper taxonomy. (This matching between the lower level of
the upper taxonomy and the top most level of the hidden taxonomy is the key to
our approach to mapping memetic expression in social discourse.)
We will use
elements of a class of adaptive elaboration instruments to enhance search and
retrieval algorithms. For example, new linguistic
variation in text categorized indicates evolution of subject indicators.
As the social discourse
changes, these patterns of linguistic variation can be empirically observed to
change and with these changes comes an evolution in nuance. These changes are
to be observed and then linked within the hidden taxonomy and the associations
between the hidden taxonomy and the upper taxonomy can be allowed to evolve as
the social discourse introduces this nuance.

Figure 3: Upper Taxonomy and Hidden Taxonomy
The upper
taxonomy continues to be fixed until or unless there are reasons to change the
upper taxonomy because of the introduction of new topics, or the forgetfulness
of topics that are no long considered relevant to the purposes of the
controlled vocabulary
Documents can
also be placed into repositories using the upper taxonomy as user defined
metadata, however search and retrieval using the Subject Matter
Indicator neighborhoods will
also use a multi-pass rule engine to provide higher resolution to the subject
indicators.
The
topology on the set of all Subject Matter Indicator neighborhoods
A machine
derived, bottom up, taxonomy can be generated in several ways. Most of the well known techniques take a set
of complex data sets and cluster the elements to introduce metaconcept
boundaries and to suggest relationships between these high order
constructions.
One way of thinking about this clustering process is that there is an implicit topology on the space of complex data sets. A method of differential ontology can be used to produce an explicit representation of these boundaries and these relationships.

Figure 4: A topology with two neighborhoods
Figure 4 could be used to produce a two level taxonomy with two nodes in the top level, one corresponding to each of the neighborhoods with “radius” = 2. Under the first top node (derived from the upper left neighborhood), we have ten subject indicators within a radius of 2 units. Under the second top node (derived from the lower right neighborhood), we also have ten subject indicators within a radius of 2 units. Neighborhoods can be made broader by taking only the underlying nodes with distance 0 and 1. In this case, the first top node would have 6 children and the second top node would have 4 children.
In the above topology, we have a simple notion of distance in graphical constructions (not trees – but more general graphic constructions). Topological logics can be used to measure the presence of subject matter indicators.
The logics we have studied include plausible reasoning and Mill’s logic. It is important to point out that the logic is not related to semantics, but rather to the identification of semantic indicators. OWL (Ontology Web Language) can be used to encode information and rules about how to detect a subject matter indicator; but we hold that a simple visualization interface is best if and when one begins to talk about the fidelity of correspondence to things in the world and behavioral causes of things in the world.
Our thoughts in this regard are consistent with the fundamental insights written into the Topic Maps standard 1.0.
Many companies have products that address concept extractions. Cost and ease of deployment are the limiting factors in bringing knowledge of these technologies to the client. Entrieva Inc and Applied technical Systems Inc both have concept extraction systems. Our technology matches any of these extraction/detection processes to the lower level of the upper taxonomy.
On the issues of adoption and use and our present need for funding
Anything that is surprising, simpler than anticipated and more powerful by several orders of magnitude when compared with previous technology is not going to be accepted easily even when understood. The initial non-acceptance is in fact understood from the very notions of autopoiesis[2][2] and the very simplest first principles of memetic science.
Memetic technology must go hand in hand with objective science based on a healthy and open interplay between theory and observation. There are social issues related to training and education. The application of this new technology to the study of memetic expression and memetic interaction is, however, immediately possible and requires only a 120-day technology development project with funding for three full time people.
A demonstration of principle has been available and has been discussed in public forums for a period of almost two years. The outline of this discussion can be viewed from the URL:
http://www.bcngroup.org/procurementModel/to-be/di.htm
The sections that follow have URLs to complete research papers and tutorials on various aspects of the new technology. In these sections we are complete and minimal in our description.
We develop a short tutorial on the core technology. Software supporting the tutorial is available at:
http://www.bcngroup.org/AIC/tutorials/3gram.zip
Community adoption and use requires a supported collaborative environment where the Orb technology is made available while also making available communication services that bring in a number of scholars who will use the memetic tools to develop a specific set of capabilities as defined in the Five Tasks listed below.
1) 1) Development of a symbolic language depicting categorical invariance in behavior related to social response under stress.
2) 2) Development of a symbolic language depicting categorical invariance in suppressive responses to aggression arising from social stress.
3) 3) Measurement technology directed at capturing the expression of causative elements of social behavior as predictors of action
4) 4) Measurement technology directed at capturing the consequences of suppressive responses to aggression.
5) 5) Development of a theoretical framework that supports predictive inference from the observations made about effects to precise knowledge about causes.
The Phase 1 of our project has identified a small group of scholars who are involved in the definition of a new memetic science. These individuals will meet several times in face-to-face conferences and will work within a distribution collaborative environment (Groove). Several memetic technologies have been identified and others may be added to the Groove toolset. As we identify this appreciative field the core team will extend a select community membership using resources judicially.
A second step will lead to the production of a red team blue team gaming environment that tests the usability of our community defined language, measurement tools and theory.
The third step will be the demonstration of the gaming environment to military leadership and the proper control of technology enabling a broad based use of the environment within the Department of Defense.
Section 2: The tutorial
Precise notational language is develop in a paper published on the Internet in December 2003:
http://www.bcngroup.org/area2/KSF/Notation/notation.htm
However, we are going to use the SLIP software invented by Paul Prueitt in 2001 to make specific examples and to point to specific objects.
We have developed several tests of “text understanding technologies” uses a small collection of 312 short stories, the Aesop fables. As we are familiar with this collection and some of the structural characteristics we choose to redevelop a study of underlying structure invariance within the fables.





