Updated
August 2, 1999 -- m. l.
On the development of a Self-Similarity Code Book
For
Fractal
Compression based Enhancement of Kinds of Self-Similarity
Dr Paul S Prueitt
Draft: Wednesday, August 04, 1999
References:
1) Fisher, Yuval (1995); Fractal Image Compression, Springer
2) Lu, Ning (Forward by Michael Barnsley) (1997); Fractal Imaging, Academic Press
3) Hubbard, Barbara (1996), The World According to Wavelets, A. K. Peters Press.
4) Pribram, Karl (1991), Brain and Perception, ERA
5) Hofstadter, D. (1995). Fluid Concepts and Creative Analogies, Basic Books.
Section 1: Image compression using codebooks have become a standard technology. The codebooks allow a replacement of n-bit size words with symbols that have a smaller binary representation. Much of the work on codebooks use some form of vector quantization and is oriented towards fast lossless data transmission.
Fractal compression takes the complete image and replaces the image information with an Iterated Function System (IFS). The individual elements in the IFS are simple affine transformations that capture specific self similarity between two regions in the image. Each of these simple transforms may be thought of as a symbol, and thus Fractal compression can be treated as a codebook compression/decompression technology.
The problem with treating the elements of IFSs as symbols in a codebook is that there are infinitely many different transformations. Initially these transforms are solved through a relationship between a domain and a range region in the images. The transform codes not only patterns of self-similarity but also relative position between self-similarity. The codes are to some extent rotationally invariant, due to the application of eight isometries in building a pool of domains. Thus the code is not a model of object invariance, nor is it the essence of some position invariant pattern or texture that can be placed into substructural memory. Absolute position is not encoded and perhaps this fact and some yet undiscovered relational operators will allow non-trivial categories (categories have more than one element) to be discovered.
Wavelets seem to be position invariant and thus to have the ability to encode less “regular” self-similarity such as Gad Yagil discusses in the early part of his paper. Yagil states that “regularity is not a necessary condition for a structure to be ordered. The digitization of medical images is likely to reflect complex order that is not regular. So the relationship between wavelet encoding and fractal encoding seems to await further experimental work. One must remember that the IFS is iterated as a global transform, but is defined from the original image using local self similarity (discovered using a computationally intensive process). The wavelet is also local, at least when compared to the Fourier transform, and takes into account a spatial foot print. This footprint has an analog to the quadtree (which is a hierarchical partitioning of the image for fractal analysis).
The IFS is used to generate, and thus to “decompress”, an approximation to the image.
We are interested in the archtyping of channels of self-similarity from one level to another and within levels. In so far as image compression helps us, then we are interested in compression techniques. In example of how compression might help us is given in the next section. However, it is quite possible that the compression research community has overlooked some obvious facts and extension of formal notation (because of the interest in speed and transmission). These overlooked facts have potential value in image understanding.
Whereas the codebook for fractal compression is generated from the image itself, it is possible to normalize individual affine transformations into various types of category sets (policies) and the related correspondences from a category to an individual symbol in a universal decompression codebook. The technique is still not worked out, but might be based on a modified Huffman coding algorithm that computes conditional probabilities of the occurrence of one type of symbol assuming a history independent Markov source.
However, there are modifications necessary, the any statistical models as in the Huffman algorithms, in order to make a linkage back into histories and forward into category policies. This linkage along lines of similarity is the key area of hierarchical similarity theory and self-similarity theory that we hope to see evolve as part of the situational logics of the tri-level (stratified) reasoning systems.
Before assuming non-Markovian sources, we need to keep it simple and get a high resolution on the relationship between the “domain and range” pairs that provide a measure of fitness within possible category policies. But a deeper assumption will have to be made to modify the Huffman coding algorithm and produce a codebook with categories matched to kinds of self similarity – and thus to metabolic processes.
We are not interested in efficient fractal coding or in efficient code transmission. Nor are we interested in avoiding the computational complexity required to identify techniques leading to feature enhancements. Because we are not interested in these sorts of things, it is possible to allow the notation and the programming to evolve in a direction that is new and productive to the task of understanding the classes of self-similarity within the photographs.
As suggested by Li et el (1995), feature enhancement, in mammography, using fractal compression can occur if the self-similarity of the targeted texture is not captured in the IFS, but the self-similarity of all other textures are captured. This enhancement method is explained and demonstrated in Section 2, below. The enhancement that we find now is very much out of focus. We suggests that if one can categorize fractal generators according to the type of natural process that produced the image captured in the picture, then one may find a new form of medical image enhancement.
Huffman codes work by studying the probability density functions (pdf) of elements from a linear segmentation of a bit steam into n bit size words. Elements with high pdfs are assigned codes that have low transmission overhead. The Huffman codes result in a lossless compression with efficiencies that come from the reduced overhead of those patterns of bits that occur more often than others. Other kinds of vector quantizations also use a codebook, often based on the selection of categories using minimization and nearest neighbor computations. So the compression and categorization theory that exists in the literature maybe helpful to our task of image understanding via a theory of substructural and object invariance. This theory and it’s resulting symbol sets and category policies can become a computational implicit memory within a tri-level architecture.
In vector quantization, a single vector represents each category, and yet there may be a number of different (but similar vectors) in each category. The number and nature of each category is carefully selected to represent a specific type of image. Because of the closeness, each of these different vectors is treated as though it was the category representative, and an appropriate code selected. Root mean square is used to form the categories in such a way as to minimize the probability of error when the next n-bits (a vector) is approximated by one of the category representatives and a substitution made at the decompression end due to this approximation. Huffman codes can then be developed to further compress the vector category representatives, and thus results in a greater compression and efficiency. However this technology is not oriented towards understand the image, but in storing and transmitting the image.
The “plane vanilla” IFS is a set of affine transformations that are discovered, for each image, using one of the pyramid type methods as discussed in the Barnsley and Fisher book and in the fractal and wavelet compression research literature. One such IFS may have as many as several thousand affine transformations. These are found using a root mean square approximation to a match between an averaged, or convolved, reduction of a region of the image (called a domain) and a second smaller region of the image called a range. A candidate affine transform is identified when the mean square root between the reduced domain and a range element is less than a threshold. This transform can be added to the IFS in order to represent the similarity at the two scales of resolution that is captured by the specific pairing of reduced domain element and range element.
One should remember that fractal generators are affine transforms developed by a computationally intensive analysis of a single image. In fractal decompression, an iterated composite of a number of generators is used to represent the whole image. At present, from what I can tell, there is no non-trivial fractal categorizations, e.g., categories having more than one element, that are used to represent properties of image textures, nor whole images. This is what we are after. We are looking to develop a collection of fractal coding categories that generate the kinds of self-similarity expressed in cancerous cellular processes and in other cellular processes.
Let look at the arithmetic. If the original image is a 1024 x 1024 image then the quadtree has ten levels with the smallest resolution being a single pixel. If we to not allow the ranges to be less than 16 * 16 then there are seven pairing opportunities, each requiring two levels, if we only compare one level to the level below. If one is able to catch the resolution just right then this staged decomposition will be optimal. However, the resolution in quadtree decomposition is arbitrarily chosen. We need a more complete view of the self-similarity and resolution.
It might be reasonable to use all partition elements from all levels about a level containing the target region. If the targeted region is a 16 x 16 region then the number of domain elements in the layers above is 2^10+2^8+2^6+2^4+2^2+1. Each of these domain elements gives rise to 8 rotations or flips (perhaps more). This large number of averaging and pairing operations can be done with the C optimized code that Fisher has given us (in his book). This is to be done for each of the 2^12 range elements.
Fractal compression is not a compression of the image, as much as the discovery of transformation of pixels arrays that when the transform is iterated there is generation of a close approximation to the original image. As the classes of self-similar codes are discovered, then they can be placed into the codebook and used without re-computing them. These codes are knowledge artifacts.
Section 2: The enhancement method
Huai Li and his colleagues explored the use of fractal compression to enhance the microcalcifications in mammography (Li et al, 1995). The technique was to compress an original image using a hand constructed IFS and then generate the resulting image (a fixed point of the iteration of the IFS). This generated image was never the same as the original (fractal compression is lossy) so when one subtracts the two images one gets a representation of those areas of the image most un represented by the similarity transforms of the chosen IFS.
Figure 1 shows the results of a similar experiment that we conducted using the compression algorithm that came in a disk packaged in the book Fractal Imaging ( Ning Li, 1997, forward by Michael Barnsley).
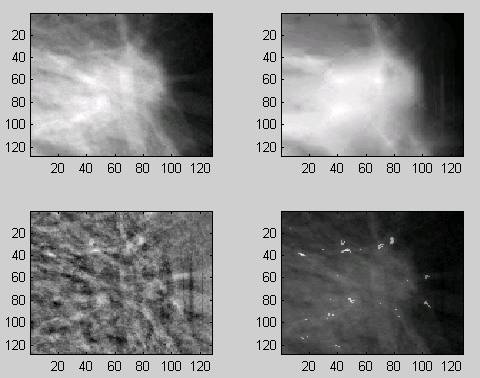
Figure 1: Experimental data on fractal enhancement of features
In running the experiment that produced Figure 1, we had no control over the selection of the IFS. The upper left corner image is the original normalized and cleaned windowed image from the GMAI image database. The upper right hand image is the fixed point of a IFS generated by the Iterated System’s commercial software (with a parameter set to encode only 80% of the resolution). The image in the lower left corner is the difference between the two upper images. This difference represents the part of the image having the greatest loss of original resolution. The lower right image is an enhancement of specific small areas where the local self-similarity is greatly different from the global self-similarity.
The objectives of both Fisher’s book (Fisher, 1995) and the Barnsley book (Nig Lu, 1997) is to reduce the loss in detail while increasing the speed of the compression. This is not our objective. Our objective is to identify kinds of self-similarity and associate classes of self-similarity to specific textures in images, and thus to specific processes that produce that texture in the image.
The process of pairing domains to ranges is a long process and can be accomplished in a number of ways. The process is nicely represented by Fisher’s Pseudo-code (page 19, Fisher 1995). The steps in this code are as follows:
1) Choose a tolerance level e.
2) Partition the full image into disjoint regions. Do this iteratively so that the first partition is composed of one element (the whole image) and the following partitions have more and more elements. This is often done by forming a quadtree partition where each level is related to the level above by inclusion and each level has four times the partition elements as the previous level. In the standard quadtree partition, each region is the same size.
3) At each iteration, of an image being partitioned into regions, a comparison is made between each element of the partition and each element of the partition at the lower level. The upper level provides a domain “pool” and the lower level provides a set of ranges. An enhanced domain pool is often formed by taking each of the partition elements, in the level above, and making eight copies using rotation by 90 degrees and flips. We want to find a contractive affine transformation that carries a reduced (averaged) domain to a range element and such at the root mean square is small. If the root mean square is small then the domain element is said to “cover” the range element.
4) If a range element is covered by a domain element, then an affine transform is easily solved for and written out.
5) If there is no domain in the domain pool that covers the range element, then the range element is partitioned in a new set of ranges and the domain pool redefined to search for a cover for one of more of these new ranges.
Ideally, the entire image would be covered by domains and the resulting affine transforms written out. This ideal is not often achieved, since there is a limit to the number of times one can partition an ever smaller set of pixels.
Variations in this process include the following:
1) the domain pool can be nominated to be other than just the set of elements in the partition “above” the partition containing the targeted range element.
2) The domain pool can be irregular in shape.
3) The pixels in a domain element are averaged into an array that has the exact size of the range element. If the reduction is one to four then one can average in four ways to get a averaged domain element. This reduction technique has many variations – some which may have specific arguments for using it. For example, the convolution of an indicator function (like a normal distribution) with a wavelet may pick up and enhance features of interest in the averaging step.
4) The enhanced domain pool may be formed by rotating at a degree other than 90. Taking the degree of rotation to be 10 would produce many more elements in an enhanced pool and perhaps capture better similarities.
5) Self similarity above the threshold might be recorded to allow a linking together of near similarity, or the development of some form of evolutionary programming to capture linkages between domain/range pairs and other domain/range pairs. This technique may lead us into a theory of the kinds of self-similarity that is seen in a single image, and also seen across a collection of images.
This draft of Thursday, August 05, 1999 is a first working document.